Spark 第三章使用 Python 开发 Spark 应用实验手册
文章导航
【实验手册版本】
当前版本号v20200316
| 版本 | 修改说明 |
|---|---|
| v20200316 | 修改实验3.3中访问 Jupytor Notebook 注意要点。 |
| v20200226 | 新增选做实验 |
| v20200214 | 初始化版本 |
实验3.1:PySpark 命令行的应用
【实验名称】
实验3.1:PySpark 的应用
【实验目的】
- 掌握PySpark 的应用
【实验原理】
- pyspark -h 查看用法
Usage: pyspark [options]
常见的[options] 如下表
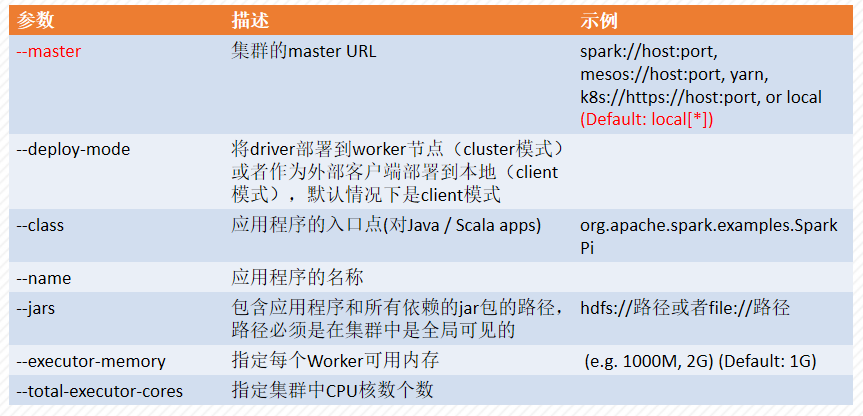
【实验环境】
- Ubuntu 16.04
- Python 3
- PySpark
- spark 2.4.4
- scala 2.12.10
【实验步骤】
1、输入pyspark -h查看各参数的定义
pyspark -h
2、查看sc变量 (1)不指定 master 时
pyspark
查看sc变量
sc
退出PySpark
quit()
(2)指定 master 时 启动 Spark
start-spark.sh
pyspark --master spark://node0:7077
查看sc变量
sc
3、使用pyspark开发一个WordCount程序。
(1)在本地创建一个文件:/home/hadoop/你的学号/wc.txt (001表示学号,请根据情况修改)。此路径也可以换为hdfs的路径。
wc.txt文件中的内容是:
Hi 你的名字
count the chicks and rabbits in the cage
chick rabbit chick rabbit chick rabbit
rabbit rabbit chick rabbit chick
chick rabbit chick rabbit chick rabbit
(2)多行代码实现WordCount。
#读取文件
r1=sc.textFile("/home/hadoop/你的学号/wc.txt")
r1.collect()
#分行
r2=r1.flatMap(lambda line:line.split(" "))
r2.collect()
#统计单词数量
r3=r2.map(lambda w:(w,1))
r3.collect()
#单词次数累加
r4=r3.reduceByKey(lambda x,y: x+y)
r4.collect()
#按次数排序
r5=r4.sortBy(lambda x:x[1],False)
r5.collect()
注:关于flatMap,map,reduceByKey等可参考书本第四章的算子部分。
(3)一行代码实现 WordCount,并输出到文件。
sc.textFile("/home/hadoop/你的学号/wc.txt").flatMap(lambda line:line.split(" ")).map(lambda w:(w,1)).reduceByKey(lambda x,y: x+y).sortBy(lambda x:x[1],False).saveAsTextFile("/home/hadoop/你的学号/wc-result")
提示:运行此命令每次需要更改saveAsTextFile后面的文件输出路径,否则会出错提示"FileAlreadyExistException"
(4)退出PySpark,访问/home/hadoop/你的学号/wc-result目录,并查看输出目录下的文件。
(5)查看结果可能由多个文件(分区)组成。尝试重复步骤(3),修改代码使用repartition方法,把结果输出到一个分区。
实验3.2:搭建 PyCharm 远程开发 Spark 应用
【实验名称】
实验3.2:搭建 PyCharm 远程开发 Spark 应用
【实验目的】
- 掌握 PyCharm 的使用
- 掌握 PyCharm 远程开发 Spark 应用
【实验原理】
- 通过 PyCharm 的设置,可以把本地电脑文件通过 SFTP 发送到虚拟机运行,从而能够实现远程的开发。
【实验资源】
- pycharm-professional-2019.3.3.exe
https://download-cf.jetbrains.com/python/pycharm-professional-2019.3.3.exe
- pycharm 安装指南
https://pan.baidu.com/s/1-9Lu6beSXCj2RYp9hwpn5A#提取码=fjji
- Python环境 Anaconda(windows平台)
https://repo.continuum.io/archive/Anaconda3-5.3.1-Windows-x86_64.exe
【实验环境】
- Ubuntu 16.04
- Python 3
- PySpark
- spark 2.4.4
- scala 2.12.10
【实验步骤】
在本机 Windows 安装 Anaconda。
安装 PyCharm professional。
查看 pycharm 安装指南进行配置。
安装完成后,打开PyCharm,新建一个名字叫
spark-exp的项目,项目路径可以自己定义,这里以D:\workspaces\workspace_python\spark-exp为例。
打开菜单"Tools -> Deployment -> Configuration…"
这里需要新建一个通过 SFTP 把本地文件远程发布到虚拟机的设置。
输入名称
hadoop@node0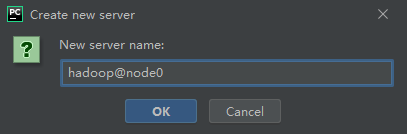
输入虚拟机的地址
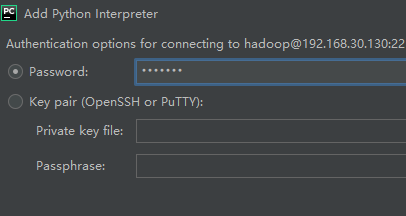
192.168.30.130,用户名hadoop,密码Hdp0668。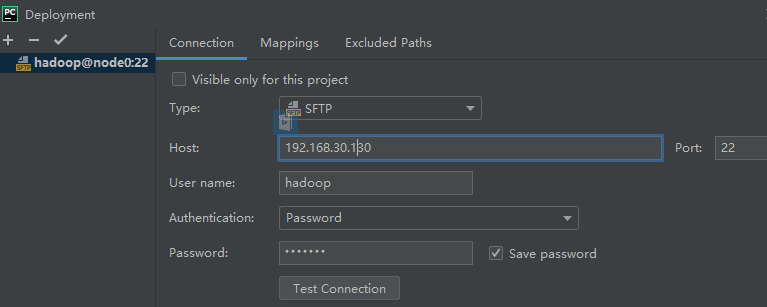
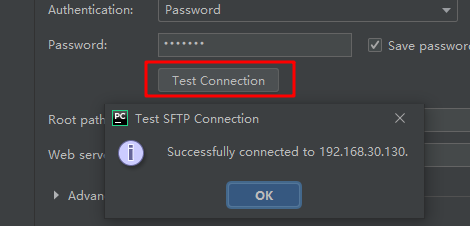
测试连接成功后,保存并退出。
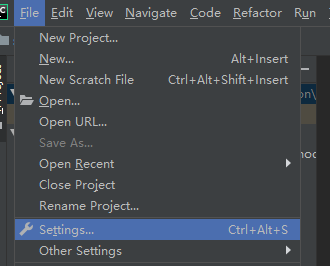
打开菜单"File -> Settings"
新增一个 Interpreter(Python解析器),这里我们需要设置虚拟机的 Python 解析器相关设定,这样我们通过 SFTP 从本地发送到虚拟机的Python 脚本才能知道使用哪个解析器进行解析运行。
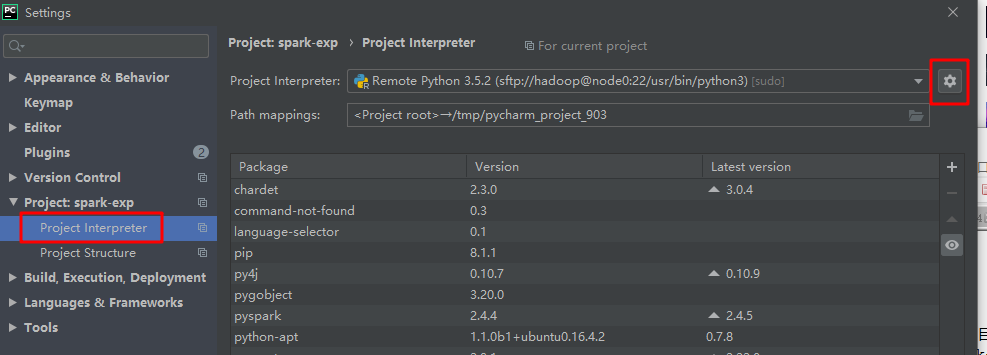

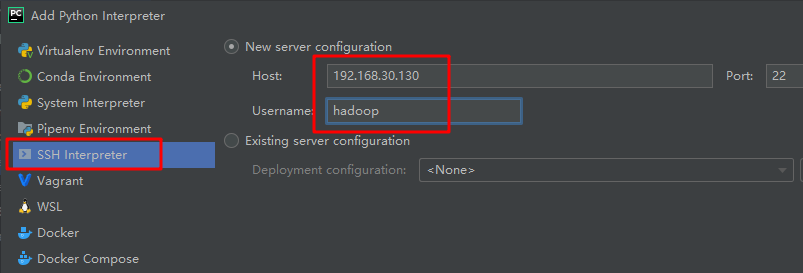
选择"ssh-interpreter",配置虚拟机的地址,用户名和密码。
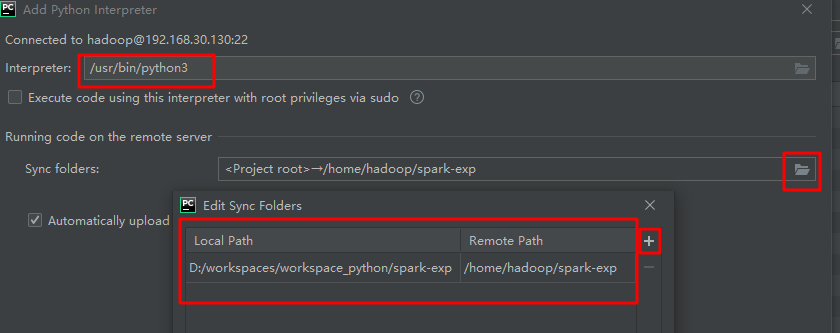
interpreter 需要选择Python的所在路径,这里设置为
/usr/bin/python3。把本地项目路径D:/workspaces/workspace_python/spark-exp映射到虚拟机的路径/home/hadoop/spark-exp,如果虚拟机路径不存在请先创建。完成以后点击"Finish"。
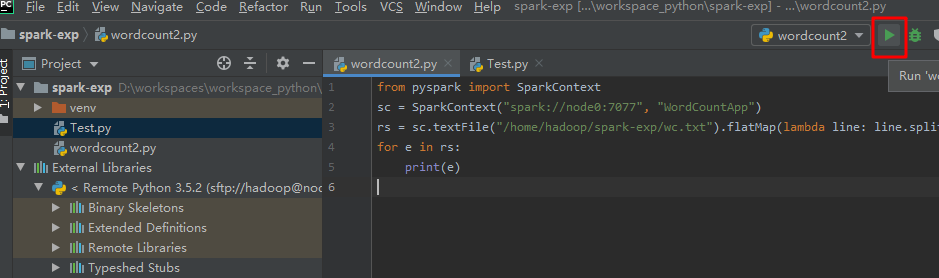
在 spark-exp 项目下新建一个 wordcount2.py 文件。
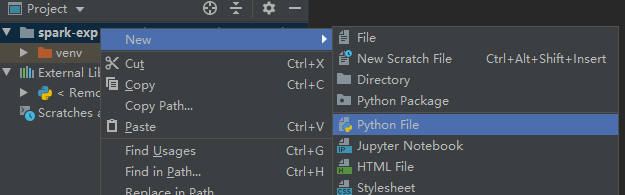
wordcount2 输入以下代码,注意修改你的学号。
from pyspark import SparkContext
sc = SparkContext("spark://node0:7077", "WordCountApp")
rs = sc.textFile("/home/hadoop/你的学号/wc.txt").flatMap(lambda line: line.split(" ")).map(lambda w: (w, 1)).reduceByKey(lambda x, y: x+y).sortBy(lambda x:x[1], False).collect()
for e in rs:
print(e)
把wordcount2.py 文件上传到虚拟机。
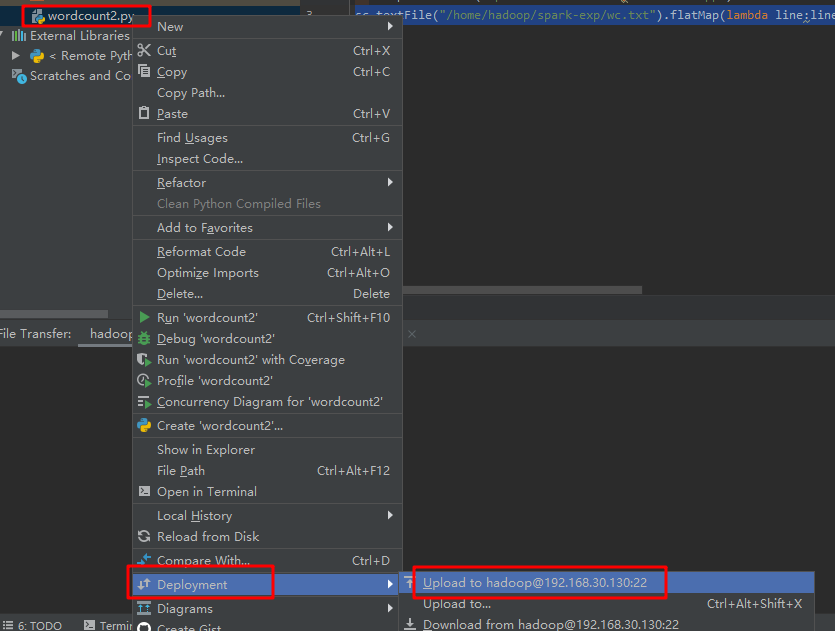
编辑 python 脚本的运行设置模板。
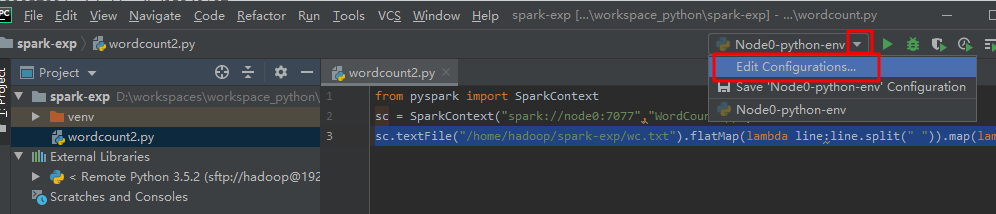
新增一个 python 运行设置模板。
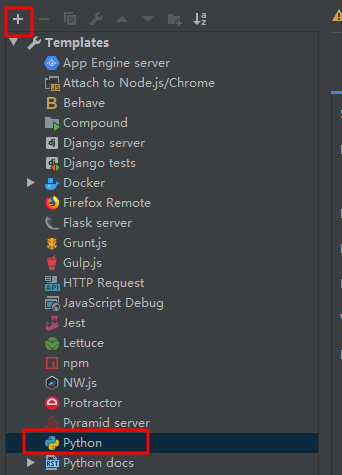
在环境变量中增加以下环境变量
SPARK_HOME /opt/spark
PYTHONPATH /opt/spark/python
JAVA_HOME /opt/jdk8
HADOOP_HOME /opt/hadoop
SCALA_HOME /opt/scala2-12
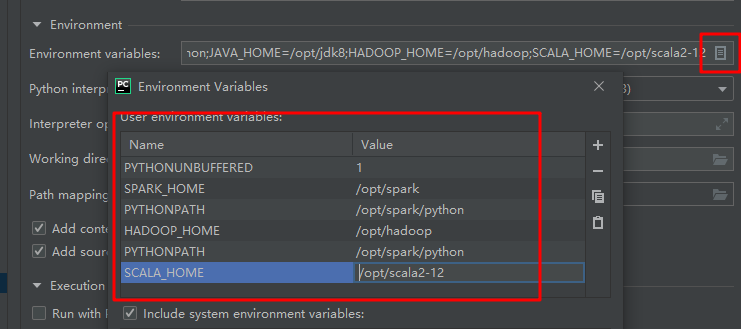
把"Script path"配置设置为本地 wordcount2.py 文件路径。“Python interpreter” 选择刚创建的解析器。
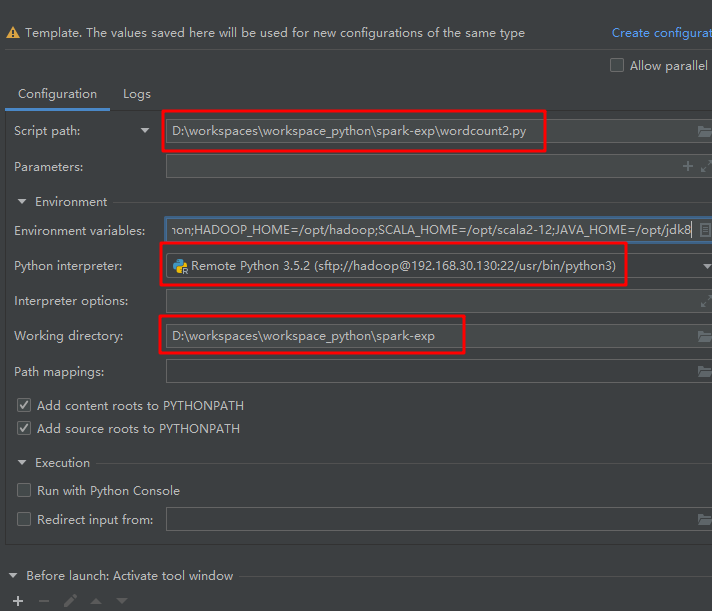
从模板创建一个运行设置
启动虚拟机的spark
start-spark.sh
- 运行 wordcount2 看是否能够得到结果。
实验3.3:搭建 Jupyter Notebook(选做)
【实验名称】
实验3.3:搭建 Jupyter Notebook(选做)
【实验目的】
- 搭建 Jupyter Notebook 开发环境
【实验原理】
Jupyter Notebook 是一个基于Web 的交互编程环境,支持多种编程语言。使用他来替代命令行交互编程可以获得更好的编程体验。
【实验环境】
- Ubuntu 16.04
- Python 3.5
- PySpark
- spark 2.4.4
- scala 2.12.10
【实验步骤】
- 配置 Python 依赖包的源,Python使用pip 来下载依赖的包。但是原有的下载源下载资源太慢,这里我们改用清华大学的安装源。
mkdir ~/.pip/
vim ~/.pip/pip.conf
- 在 pip.conf 文件里面输入以下内容,修改源为清华大学源。
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host = pypi.tuna.tsinghua.edu.cn
- 通过网络下载安装 Jupyter Notebook 前,先检查一下能否连接互联网,如果命令没有响应,请返回实验2检查网络安装和配置。
#测试能否联网
ping baidu.com
- 安装 Jupyter Notebook。
pip3 install notebook
- 因为安装 ipython 版本和 Python3.5 不兼容,所以卸载自带 ipython,安装7.9.0版本。
pip3 uninstall ipython
pip3 install ipython==7.9.0
- 安装 findspark,主要用来检测spark运行。
pip3 install findspark
- 修改 PySpark 的驱动命令,修改为使用 Jupyter Notebook。
vim /opt/spark/conf/spark-env.sh
找到这句,注释掉。
#export PYSPARK_DRIVER_PYTHON=python3
- 在用户的环境变量配置文件增加 PYSPARK 驱动配置。 (1)用户的环境变量配置
vim ~/.bashrc
(2)在文件最后加入
#由于上文注释掉此选项以后,pyspark 将不能在SSH终端(例如Xshell)输入 Python 代码,而是自动启动 Jupyter Notebook,用户可以在 Notebook 输入代码。
export PYSPARK_DRIVER_PYTHON=jupyter
#--ip=* 选项主要是为了启动 Jupyter 服务器可以绑定所有IP,浏览器可以访问。
export PYSPARK_DRIVER_PYTHON_OPTS='notebook --ip=*'
(3)让配置生效
source ~/.bashrc
- 启动PySpark,查看是否能够启动 Jupyter Notebook。
pyspark
复制命令行下 Jupyter Notebook 的地址。

注意:
- Jupyter Notebook每次地址token参数会不一样。
- 如果 Jupyter Notebook 地址不能访问可以替换 node0 为虚拟机 IP 地址,或者编辑 Windows 的 host 文件(C:\Windows\System32\drivers\etc\hosts),增加一行"192.168.30.130 node0",把node0指向虚拟机地址,即可访问。
- 访问 Jupyter Notebook 的地址,新建一个文件,Jupyter 会自动在你启动的目录下生成一个
Untitled.ipynb的文件来保存你输入的代码。
提示:
- 在命令行按下
Ctrl+C可以停止 Jupyter Notebook。- 如果安装了 Jupyter Notebook,原本 PySpark 的命令行交互方式就不能再使用了。如果想要恢复,就把第7步注释的部分还原,把第8步的环境变量配置注释掉。
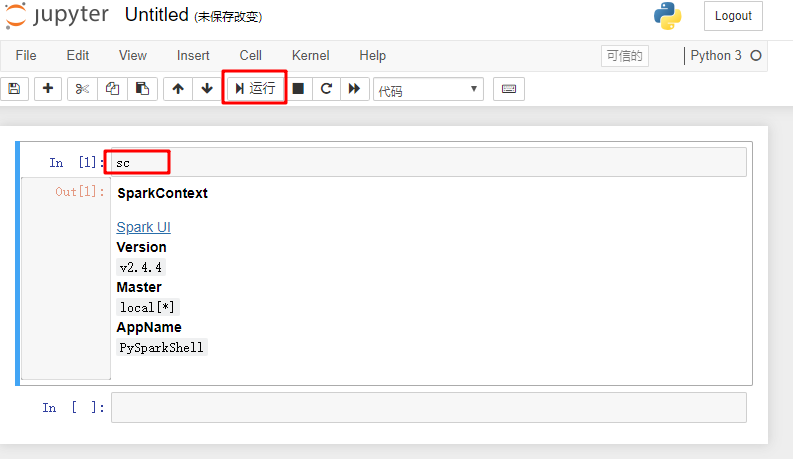
自行探索 Jupyter Notebook 的保存,编辑等功能。
重复执行试验3.2 的 wordcount 部分代码,检验 Jupyter Notebook 是否正常运行。