Spark 第二章搭建 Spark 实验手册
文章导航
实验2.1:搭建 Spark Standalone 模式
【版本】
当前版本号v20200318
| 版本 | 修改说明 |
|---|---|
| v20200318 | 修改了第16步脚本路径 |
| v20200229 | 增加了hosts的设置 |
| v20200210 | 初始化版本 |
【实验目的】
- 掌握搭建 Spark Standalone 模式
- 熟练掌握Linux命令(vi、tar、环境变量修改等等)的使用
- 掌握VMWare、XShell、Xftp等客户端的使用
【实验原理】
Spark支持多种分布式部署方式,至少包括:
- Standalone单独部署(伪分布或全分布),不需要有依赖资源管理器。
- Hadoop YARN(也即Spark On Yarn),部署到Hadoop YARN资源管理器。
- Apache Mesos,部署到Apache Mesos资源管理器。
- Amazon EC2,部署到Amazon EC2资源管理器。
这里主要学习单独(Standalone)部署中的伪分布模式的搭建。
【实验环境】
- 内存:至少4G
- 硬盘:至少空余40G
- 操作系统: 64位 Windows系统。
【实验资源】
以下非网盘实验资源推荐复制链接到迅雷下载。
- 虚拟机软件
https://pan.baidu.com/s/1CaDXO0GmJ2ocy7Gtuef47Q#提取码=fjks
- 虚拟机镜像
https://pan.baidu.com/s/1g0Ji1wY07JxffhhHo14cIQ#提取码2txb
- XShell
https://pan.baidu.com/s/1e8isFVpfw90sps2WtxLZOQ#提取码=jef5
- scala-2.12.10.tgz
http://distfiles.macports.org/scala2.12/scala-2.12.10.tgz
- spark-2.4.4-bin-hadoop2.7.tgz
https://archive.apache.org/dist/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz
【实验步骤】
安装 VMWare WorkStation、XShell 如果已经安装请忽略。 安装过程略。
导入老师提供的 Node0 虚拟机镜像。 打开虚拟机->找到 Node0 文件夹下的 vmx 文件进行 导入。 注意:请分配给你的虚拟机至少2G内存。
右键点击虚拟机 Node0,选择“设置..”。配置网络适配器到 VMnet1 。
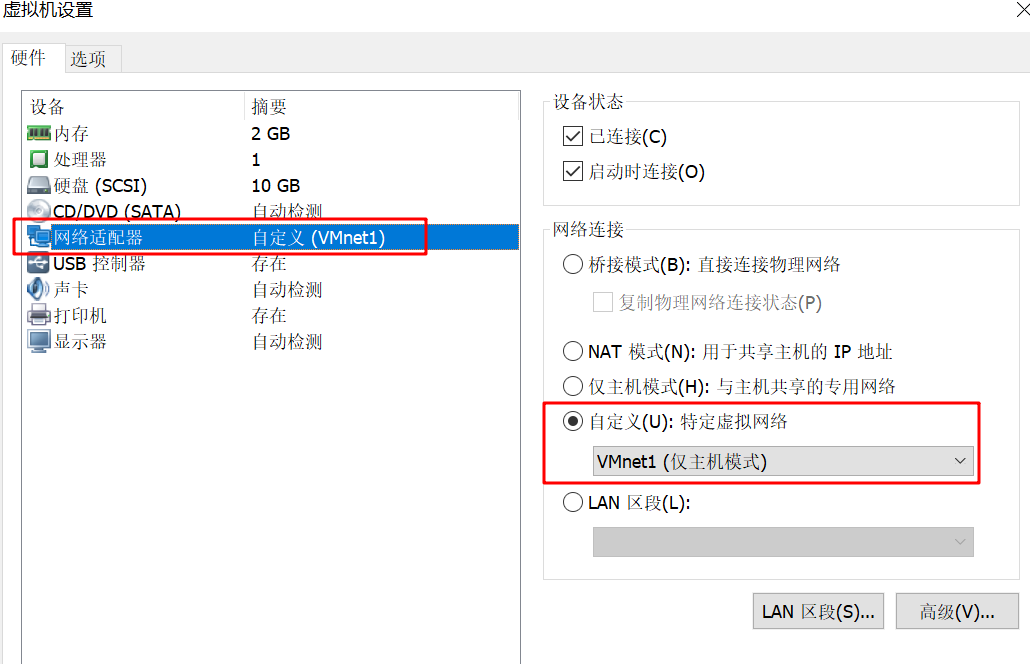
进入电脑“控制面板\网络和 Internet\网络连接”,查看VMWare 的VMnet1虚拟网卡的属性,并配置 IP 为
192.168.30.1。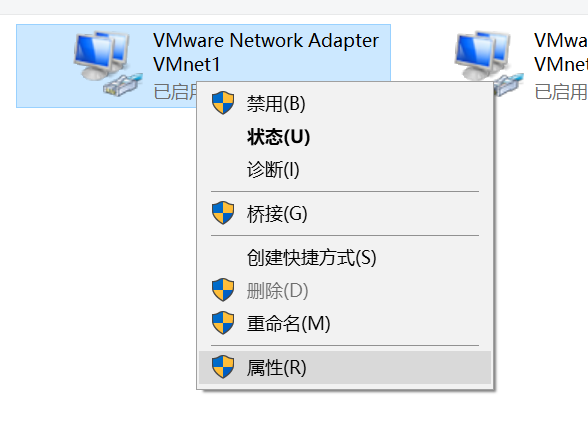
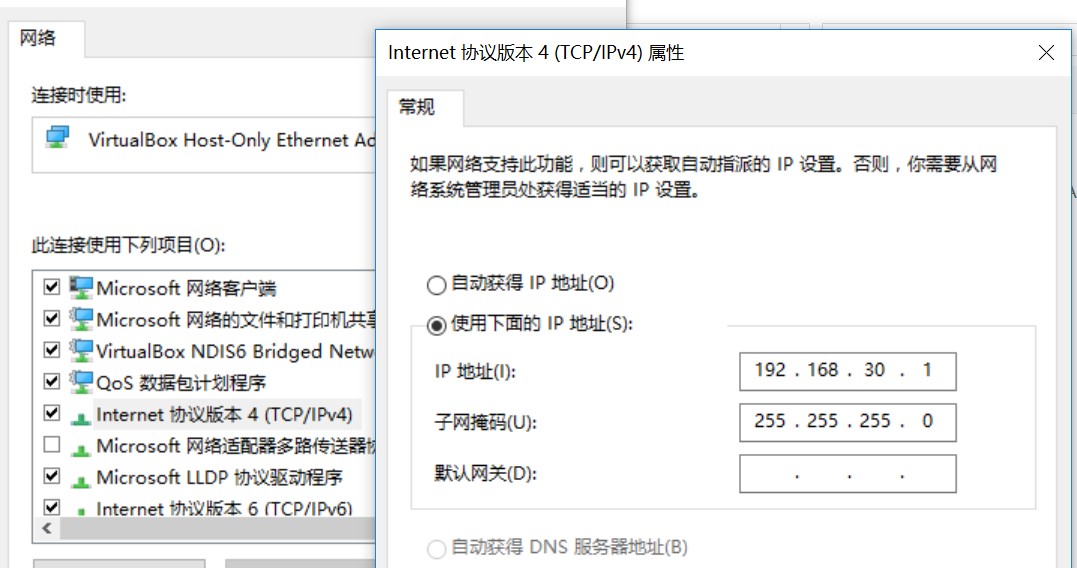
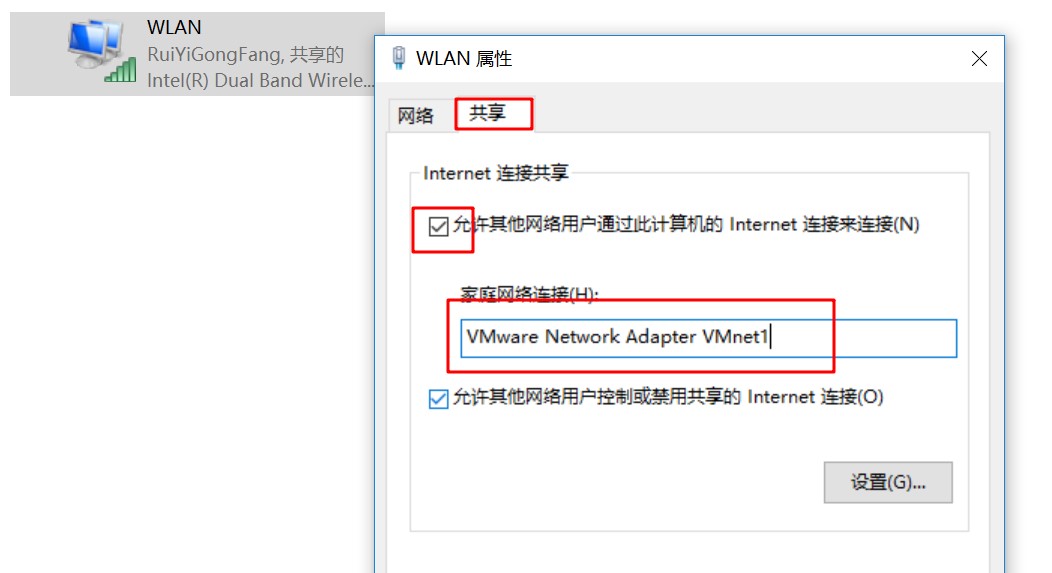
选择能够上网的网卡(无线上网选择无线网卡,有线上网则选择有线网卡),让上网的网卡共享给 VMWare 的虚拟网卡VMnet1。
启动 Node0 镜像,使用 XShell SSH 登录到 Node0。
用户名:hadoop
密码:Hdp0668
IP:192.168.30.130
- 进入网卡设置,检查IP,网关和网卡设置是否一致。
(1)查看网卡名称和IP地址
ip addr
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:49:ea:f6 brd ff:ff:ff:ff:ff:ff
inet 192.168.30.130/24 brd 192.168.30.255 scope global ens33
(2)编辑网卡设置,注意其中的ens33是网卡名称和上文网卡名称要保持一致。
sudo vim /etc/network/interfaces
auto ens33
#iface ens33 inet dhcp
iface ens33 inet static
address 192.168.30.130
netmask 255.255.255.0
gateway 192.168.30.1
- 运行以下命令,检查网络是否畅通。如果没有回应则检查你之前的网络配置步骤是否出错。
ping 192.168.30.1
ping baidu.com
- 配置免密登录
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
- 检查环境。 (1)分别逐行运行以下命令查看预装的 Python3 和 Java 版本和安装路径。
#查看 JDK 版本
java -version
#查找 java 命令所在路径
whereis java
#查看 Python 版本
python -V
#查找 python3 命令所在路径
whereis python3
(2)把python3命令拷贝为python命令
sudo cp /usr/bin/python3 /usr/bin/python
(3)修改hosts,指向hostname。
sudo vim /etc/hosts
127.0.0.1 node0
(4)另外系统也预装了MySQL,并在/opt目录下预装了Hadoop 伪分布式、Hive、Pig。
#Hadoop 的启动和停止脚本修改为
start-hdp.sh
stop-hdp.sh
#启动Hive
hive
#启动Pig
pig
#查看Hadoop相关进程
jps
- 系统预装软件的环境变量的配置放在了
/etc/profile.d/set-env.sh,需要提升权限编辑。
sudo vim /etc/profile.d/set-env.sh
上传 scala 和 spark 的安装包。
使用
tar -xvf解压 scala 和 spark 包,并移动到/opt目录下。例如以下的目录结构。
/移动 Scala 和 Spark 目录到 /opt
sudo mv scala-2.12.10 /opt/scala-2-12
sudo mv spark-2.4.4-bin-hadoop2.7 /opt/spark
- 编辑环境变量
(1)加入 SCALA_HOME 和 SPARK_HOME
SCALA_HOME=/opt/scala-2-12
SPARK_HOME=/opt/spark
export PYSPARK_PYTHON=python3
PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$HIVE_HOME/bin:$PIG_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin:$SCALA_HOME/bin:$PATH:.
(2)让环境变量生效
source /etc/profile.d/set-env.sh
- 配置 Spark
(1)编辑spark-env.sh
cd $SPARK_HOME/conf
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
#spark-env.sh 配置
#Spark executor 可以使用的CPU核心数量,可以根据自己电脑和虚拟机情况来配置。
SPARK_EXECUTOR_CORES=2
#Spark master 绑定hostname
SPARK_MASTER_HOST=node0
#Spark worker 可以使用的CPU核心数量,可以根据自己电脑和虚拟机情况来配置。
SPARK_WORKER_CORES=2
#Spark worker 最大内存分配量
SPARK_WORKER_MEMORY=2g
#在文件最后加入以下配置,PySpark 的 Python 命令指定为 python3
alias python=python3
export JAVA_HOME=/opt/jdk8
export SCALA_HOME=/opt/scala-2-12
export PYSPARK_DRIVER_PYTHON=python3
export PYSPARK_PYTHON=python3
export LD_LIBRARY_PATH=/opt/hadoop/lib/native/
(2)编辑 slaves
cp $SPARK_HOME/conf/slaves.template $SPARK_HOME/conf/slaves
#底部加入本机hostname
node0
(3)复制日志配置
cd $SPARK_HOME/conf
cp log4j.properties.template log4j.properties
- 修改 Spark 启动脚本名称。
(1)在Spark启动脚本加入你的个人学号。
vim $SPARK_HOME/sbin/start-all.sh
#在第二行加入以下内容,注意替换为你的学号
echo "Start by 你的学号"
(2)修改启动脚本的名称。
cd $SPARK_HOME/sbin
mv start-all.sh start-spark.sh
mv stop-all.sh stop-spark.sh
- 离线安装PySpark。
cd $SPARK_HOME/python
sudo python3 setup.py install
- 启动 Spark,并验证。
(1)输入启动脚本,并输入 jps 查看是否有 Worker 和 Master 进程
start-spark.sh
jps
(2)使用本机电脑浏览器访问http://虚拟机IP地址:8080,查看 Spark 工作网页是否正常。
(3)运行pyspark --master spark://node0:7077 查看 PySpark 是否安装成功。(可以使用quit()命令退出pyspark)
实验2.2:使用 spark submit 命令
【实验名称】
实验2.2:使用 spark submit 命令
【实验目的】
- 掌握 spark submit 命令
- 了解蒙特卡罗(Monte Carlo)方法计算圆周率的方法 正方形内部有一个相切的圆,假设圆的半径为R,则圆形和正方形面积分别是πR2和4R2,它们面积之比是π/4。如果使用大量点随机填充到正方形内,那么只需要计算圆内的点(即点到圆心距离小于圆半径)占到所有点的比例,即可推导出 π 的近似值。

【实验原理】
spark-submit -h可以查看用法Spark Master URL参数解析
| 参数 | 说明 |
|---|---|
| local | 使用一个 Worker 线程本地化运行 Spark(默认) |
| local[k] | 使用 k 个 Worker 线程本地化运行 Spark |
| local[*] | 使用 k 个 Worker 线程本地化运行 Spark(这里 K 自动设置为机器的 CPU 核数) |
| spark://HOST:PORT | 连接到指定的 Spark 单机版集群 master。必须使用 master 所配置的接口,默认接口 7077,如 spark://10.10.10.10:7077。 |
| mesos://HOST:PORT | 连接到指定的 mesos 集群。host 参数是 moses master 的 hostname。必须使用 master 所配置的接口,默认接口是 5050。 |
| yarn-client | 以客户端模式连接到 yarn 集群,集群位置由环境变量 HADOOP_CONF_DIR 决定。 |
| yarn-cluster | 以集群模式连接到 yarn 集群,同样由 HADOOP_CONF_DIR 决定连接。 |
【实验环境】
- Ubuntu 16.04
- Spark2.x
【实验步骤】
- 输入
spark-submit -h查看各参数的定义
spark-submit -h
- 执行下面几种 spark-submit 方式。注意:在运行后注意打开网页http://[IP地址]:8080,查看是否有应用程序(Application)。
(1)方式1:没有指定“–master”
spark-submit --class org.apache.spark.examples.SparkPi /opt/spark/examples/jars/spark-examples_2.11-2.4.4.jar 100
注:这里的100作为参数传入 SparkPi 类,是指把计算集分区数量。
(2)方式2:指定“–master”为local
spark-submit --master local --class org.apache.spark.examples.SparkPi /opt/spark/examples/jars/spark-examples_2.11-2.4.4.jar 100
(3)方式3:指定“–master”为local[2]
spark-submit --master local[2] --class org.apache.spark.examples.SparkPi /opt/spark/examples/jars/spark-examples_2.11-2.4.4.jar 100
(4)方式4:指定“–master”为local[*]
spark-submit --master local[*] --class org.apache.spark.examples.SparkPi /opt/spark/examples/jars/spark-examples_2.11-2.4.4.jar 100
(5)方式5:指定“–master”为spark://hostname:7077
先启动 Spark
start-spark.sh
spark-submit --master spark://node0:7077 --class org.apache.spark.examples.JavaSparkPi /opt/spark/examples/jars/spark-examples_2.11-2.4.4.jar 100
(6)方式6:运行py文件
spark-submit --master spark://node0:7077 /opt/spark/examples/src/main/python/pi.py 100
注:以下为pi.py的源码
import sys
from random import random
from operator import add
from pyspark import SparkContext
if __name__ == "__main__":
"""
Usage: pi [partitions]
"""
sc = SparkContext(appName="PythonPi")
#传入的参数作为分区数量
partitions = int(sys.argv[1]) if len(sys.argv) > 1 else 2
#点的数量,每个分区10万个点
n = 100000 * partitions
#如果到圆心距离小于1(即圆半径),返回1,表示在圆面积以内
def f(_):
x = random() * 2 - 1
y = random() * 2 - 1
return 1 if x ** 2 + y ** 2 < 1 else 0
#累计圆面积内的点数
count = sc.parallelize(xrange(1, n + 1), partitions).map(f).reduce(add)
#推导Pi的近似值
print "Pi is roughly %f" % (4.0 * count / n)
sc.stop()