Hadoop大数据集群部署实战 Part 5 - 使用 MapReduce 和 Hive 进行数据分析
文章导航
Hadoop大数据集群部署实战 Part 5 - 使用 MapReduce 和 Hive 进行数据分析
【版本】
当前版本号v20210521
| 版本 | 修改说明 |
|---|---|
| v20210521 | 初始化版本 |
数据分析实训5.1 - 在电影库中查找我的演员评分最高的5部电影
【实训名称】
数据分析实训5.1 - 在电影库中查找我的演员评分最高的5部电影
【实训目的】
- 掌握 MapReduce 的 Mapper 编写
- 掌握 MapReduce 序列化的使用
- 掌握 MapReduce 的排序
【实训环境】
- Windows 7+
- VMWare Workstation Pro
- CentOS 7
- Hadoop 2.7.3
- JDK 版本:1.8 或以上版本。
【实训资源】
- 软件资源
链接:https://pan.baidu.com/s/1xYCO5mT2mxZGkda6j3mtdg
提取码:heis
- 项目代码
链接:https://pan.baidu.com/s/1DcLksXdp_xbqv1fOBeF-UA
提取码:heis
Film.json是豆瓣电影的真实电影数据。里面包含了41960部电影数据。其中各个字段解释如下表
| 字段名 | 注释 |
|---|---|
| title | 电影名 |
| year | 上映年份 |
| type | 电影类型 |
| star | 电影评分2-10分 |
| director | 导演 |
| actor | 演员 |
| time | 电影时长 |
| film_page | 电影信息链接 |
【实训要求】
(1)在表格学生演员分配.xlsx里找到分配给你的演员。
(2)结合本门课程学过的知识,编写 MapReduce 程序,按评分从高到低排序该演员参演电影(如果同分则优先列出年份较近的,例如2000年上映的A电影和1995年上映的B电影同分,则排序应该为A,B),找到评分最高的前5部电影的名称,上映年份和评分。
【提示1 序列化和排序】
使用 IDEA 打开 hdp-training-exp1 项目。
运行
src/test/java/hadoop9999/training/exp1/test/HadoopSerializationTest.java单元测试。此单元测试展示了在 MapReduce 中,键值对中的对象序列化的代码。如果只需要对对象进行序列化,只需要实现
org.apache.hadoop.io.Writable接口。如果同时要对对象进行序列化,同时也需要对对象进行排序,需要实现
org.apache.hadoop.io.WritableComparable接口。MapReduce 的排序主要是利用了在 Shuffle 阶段对键值对中的键(Key)进行的排序。
【提示2 如何对把 JSON 转换为 Java 对象】
使用 IDEA 打开 hdp-training-exp1 项目。
运行
src/test/java/hadoop9999/training/exp1/test/JsonParseTest.java单元测试。此单元测试展示了如果把 JSON 的字符串转换为 Java 对象。
【提示3 如何对 Mapper 进行测试】
使用 IDEA 打开 hdp-training-exp1 项目。
运行
src/test/java/hadoop9999/training/exp1/test/MapperTest.java单元测试。此单元测试展示了如何对 MapReduce 中的 Mapper 进行测试。
数据分析实训5.2 - 在电影库中查找我的演员合作次数最多的演员及其合作作品。
【实训名称】
数据分析实训5.2 - 在电影库中查找我的演员合作次数最多的演员及其合作作品。
【实训目的】
- 掌握使用 Hive 进行数据分析
【实训环境】
- Windows 7+
- VMWare Workstation Pro
- CentOS 7
- Hadoop 2.7.3
- JDK 版本:1.8 或以上版本。
- Hive 2.3.8
【实训资源】
- 软件资源
链接:https://pan.baidu.com/s/1xYCO5mT2mxZGkda6j3mtdg
提取码:heis
- 项目代码
链接:https://pan.baidu.com/s/1DcLksXdp_xbqv1fOBeF-UA
提取码:heis
Film.json是豆瓣电影的真实电影数据。里面包含了41960部电影数据。其中各个字段解释如下表
| 字段名 | 注释 |
|---|---|
| title | 电影名 |
| year | 上映年份 |
| type | 电影类型 |
| star | 电影评分2-10分 |
| director | 导演 |
| actor | 演员 |
| time | 电影时长 |
| film_page | 电影信息链接 |
【实训要求】
(1)在表格学生演员分配.xlsx里找到分配给你的演员。
(2)结合本门课程学过的知识,编写程序(Java程序/MapReduce)对’Film.json’内容进行筛选,筛选出只包含你的演员演过的电影,并转换为 csv 格式。
(3)把转换后csv文件导入 Hive,使用 SQL 查询和我的演员合作次数最多的前5位演员及其合作最高分的作品(如果同分则优先列出年份较近的,例如2000年上映的A电影和1995年上映的B电影同分,则排序应该为A,B)。需要展示演员姓名,合作次数,以及合作最高分的作品名称和评分。
【提示1 JSON 转换 CSV 格式】
实训5.1已经提示了如何把 JSON 格式转换为 Java 的对象。这里JSON可以先转换为 Java 对象,再转换为CSV。CSV的格式非常简单,使用分行符表示1行数据,每个单元数据使用英文的逗号
,隔开。在转换的过程中,我们可以考虑只筛选有我的演员参演的电影。参考代码如下:
String actor="我的演员姓名";
// 获取 Film.json 文件的绝对路径
String filmJsonPath=Json2Csv.class.getClassLoader().getResource("Film.json").getPath();
//读取Film.json
BufferedReader br=new BufferedReader(new FileReader(filmJsonPath));
//MovieInfo 类可以参考实验1
MovieInfo m=null;
String line;
while((line=br.readLine())!=null){
//Fastjson 把每行的json 字符串转换为对象。
m= JSON.parseObject(line,MovieInfo.class);
//过滤并把每部电影合作的每个演员,都转为包含电影信息1行csv数据
if(m.getActor().indexOf(actor)!=-1){
//找到我的演员的电影,接下来把对象转换为csv,代码略。
...
}
}
- 在转换为 CSV 格式的时候,为了方便我们后续分析,可以考虑转换1行 JSON 为多行的 CSV 数据,这样在统计演员合作次数的时候会更容易统计。例如以下 JSON 数据,可以考虑转换为示例中的 CSV 格式。
{"_id":{"$oid":"5ad930de6afaf81ac48844a0"},"title":"重庆森林 重慶森林","year":"1994","type":"剧情,爱情","star":8.7,"director":"王家卫","actor":"林青霞,金城武,梁朝伟,王菲,周嘉玲","pp":358053,"time":102,"film_page":"https://movie.douban.com/subject/1291999/"}
转换以后,只需要包含film_page、title、actor、star 这几列。这时候统计演员的合作次数只需要统计每个演员出现的次数就可以了。
https://movie.douban.com/subject/1291999/,重庆森林 重慶森林,林青霞,8.7
https://movie.douban.com/subject/1291999/,重庆森林 重慶森林,金城武,8.7
https://movie.douban.com/subject/1291999/,重庆森林 重慶森林,梁朝伟,8.7
https://movie.douban.com/subject/1291999/,重庆森林 重慶森林,王菲,8.7
https://movie.douban.com/subject/1291999/,重庆森林 重慶森林,周嘉玲,8.7
数据分析实训5.3 - 使用数据可视化技术展示我的演员电影产量和质量按年份的变化。
【实训名称】
数据分析实训5.3 - 使用数据可视化技术展示我的演员电影产量和质量按年份的变化。
【实训目的】
- 掌握使用 Hive 进行数据分析
【实训环境】
- Windows 7+
- VMWare Workstation Pro
- CentOS 7
- Hadoop 2.7.3
- JDK 版本:1.8 或以上版本。
- Hive 2.3.8
【实训资源】
- 软件资源
链接:https://pan.baidu.com/s/1xYCO5mT2mxZGkda6j3mtdg
提取码:heis
- 项目代码
链接:https://pan.baidu.com/s/1DcLksXdp_xbqv1fOBeF-UA
提取码:heis
Film.json是豆瓣电影的真实电影数据。里面包含了41960部电影数据。其中各个字段解释如下表
| 字段名 | 注释 |
|---|---|
| title | 电影名 |
| year | 上映年份 |
| type | 电影类型 |
| star | 电影评分2-10分 |
| director | 导演 |
| actor | 演员 |
| time | 电影时长 |
| film_page | 电影信息链接 |
【实训要求】
(1)在表格学生演员分配.xlsx里找到分配给你的演员。
(2)结合本门课程学过的知识,编写程序(Java程序/MapReduce)对’Film.json’内容进行筛选,筛选出只包含你的演员演过的电影,并转换为 csv 格式。
(3)把转换后csv文件导入 Hive,使用 SQL 分析我的演员每年上映的电影的数量和平均分。
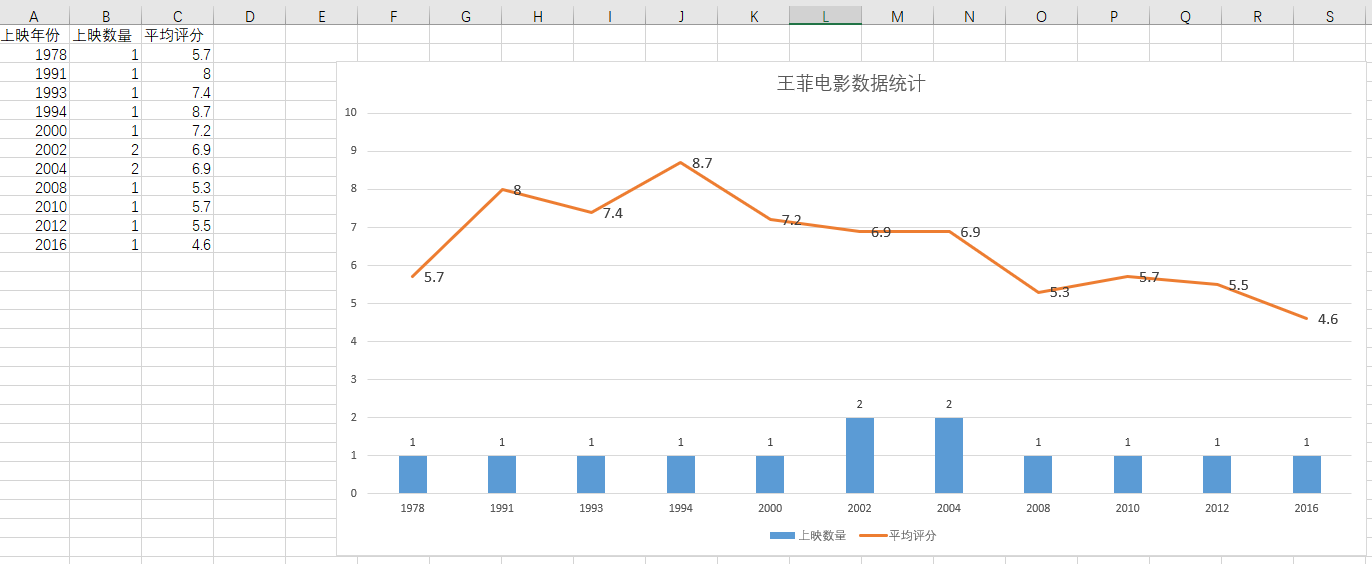
(4)使用可视化工具(例如 Excel 等)把数据转换为可视化的图表,需要包含该演员每年电影上映数量和上映所有电影的平均分。图表形式可以使用折线图,柱状图等。
如:下图是使用 Excel 制作的“王菲的电影信息可视化图表”