Hadoop Part 2 - 部署 Hadoop 完全分布模式
文章导航
Hadoop Part 2 - 部署 Hadoop 完全分布模式
【版本】
当前版本号v20210415
| 版本 | 修改说明 |
|---|---|
| v20210415 | 修改了虚拟机名称的描述避免误解为hostname |
| v20210414 | 修改了步骤1,提示要使用hadoop用户进行登录 |
| v20210408 | 新增配置到core-site.xml,修正jobhistoryserver意外退出的问题 |
| v20210407-1 | 修正NodeB和NodeC的公钥操作 |
| v20210407 | 修正authorized_keys 在 NodeB 和 NodeC 的操作 |
| v20210406 | 修改了mapred-site.xml出现的配置错误;新增了把key写入 authorized_keys 步骤;增加了slaves的说明,避免出错; |
| v20210319 | 初始化版本 |
【实验名称】
Hadoop Part 2 - 部署 Hadoop 完全分布模式
【实验目的】
- 掌握搭建 Hadoop 完全分布模式
- 熟练掌握Linux命令(vi、tar、mv等等)的使用
- 掌握VMWare、XShell等客户端的使用
【实验环境】
- 内存:至少4G
- 硬盘:至少空余40G
- 操作系统: 64位 Windows系统。
【实验资源】
- XShell
- CentOS 7.4系统镜像
- VMWare WorkStation Pro
- Hadoop 安装包
下载链接:https://pan.baidu.com/s/1ghde86wcK6pwg1fdSSWg0w
提取码:v3wv
【虚拟机操作实验步骤】
- 关闭 Part1 完成的 HadoopTmpl 模板机。依次克隆出3台虚拟机,名称,主机名和 IP 地址如下表所示,注意替换为你的学号后4位。
| 虚拟机名称 | hostname | IP地址 |
|---|---|---|
| 节点A主机(Namenode) | nodea+你学号后4位 | 10.0.0.71 |
| 节点B主机(Datanode) | nodeb+你学号后4位 | 10.0.0.72 |
| 节点C主机(Datanode) | nodec+你学号后4位 | 10.0.0.73 |
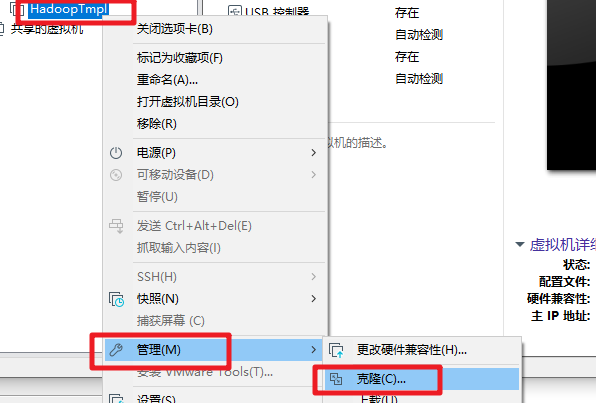
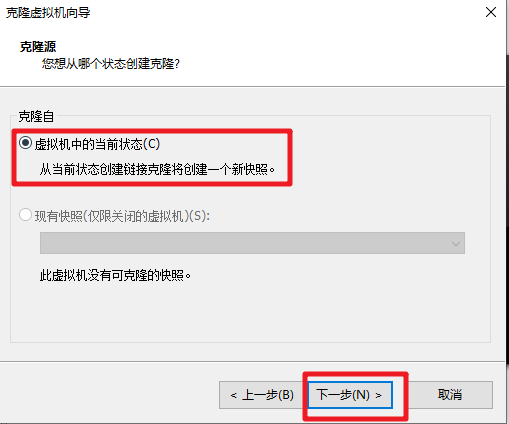
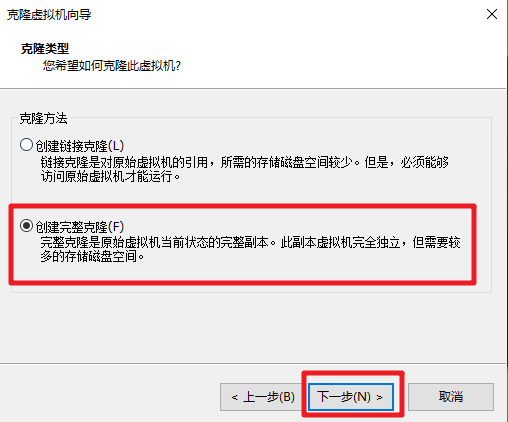
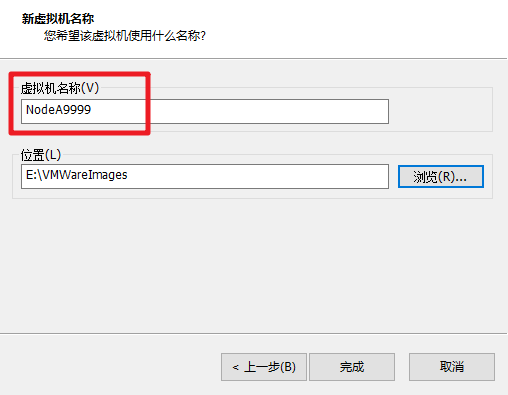
- 依次启动克隆的虚拟机,修改为对应的 hostname 和 IP。
vim /etc/hostname
vim /etc/sysconfig/network-scripts/ifcfg-eth0
- 重启克隆的3台虚拟机,配置 XShell 连接虚拟机,使用
hadoop用户登录,密码为123456。
【NodeA节点实验步骤】
- 使用 Hadoop 用户登录 NodeA 节点。如果使用root登录的可以使用以下命令切换到hadoop用户。
su hadoop
- 配置免密登录。首先生成密钥对,运行以下命令,直接回车(Enter)3次。
ssh-keygen -t rsa
- 查看目录下是否有公钥
id_rsa.pub和私钥id_rsa。
cd ~/.ssh
ls
- 执行以下命令,把公钥写入本机授权文件。
cat id_rsa.pub >> authorized_keys
- 查看授权文件内的公钥内容。
cd ~/.ssh
cat authorized_keys
- 启动
NodeB和NodeC2个节点。在NodaA上面运行以下命令,把公钥拷贝到NodeB和NodeC。
ssh-copy-id -i ~/.ssh/id_rsa.pub nodeb+你学号后4位 -f
ssh-copy-id -i ~/.ssh/id_rsa.pub nodec+你学号后4位 -f
#系统询问是否连接,输入yes
Are you sure you want to continue connecting (yes/no)? yes
#输入 hadoop 登录密码
hadoop@nodeb9999's password:
- 在
NodeB和NodeC2个节点分别执行以下命令,查看是否包含来自NodeA的公钥。
cat authorized_keys
- 备份和编辑 Hadoop 的 core-site.xml 配置文件。在configuration 标签内添加配置,注意替换为你的学号后4位。
cp /opt/hadoop/etc/hadoop/core-site.xml{,.bak}
vim /opt/hadoop/etc/hadoop/core-site.xml
<configuration>
<!-- HDFS 访问地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://nodea+你学号后4位:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
</configuration>
- 备份和编辑 Hadoop 的 hdfs-site.xml 配置文件。请注意替换为你的学号。
cp /opt/hadoop/etc/hadoop/hdfs-site.xml{,.bak}
vim /opt/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<!-- secondary namenode 访问地址-->
<property>
<name>dfs.secondary.http.address</name>
<value>nodea+你学号后4位:50090</value>
</property>
<!-- HDFS 副本数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
- 新建一个 masters 配置文件,写入 Secondary NameNode 的主机名。
vim /opt/hadoop/etc/hadoop/masters
写入以下内容,注意替换为你的学号后4位。
nodea+你的学号后4位
- 备份和编辑 Hadoop 的 mapred-site.xml 配置文件。注意替换为你的学号后4位。
cp /opt/hadoop/etc/hadoop/mapred-site.xml.template /opt/hadoop/etc/hadoop/mapred-site.xml
vim /opt/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>nodea+你学号后4位:10020</value>
<description>Host and port for Job History Server (default 0.0.0.0:10020)</description>
</property>
</configuration>
- 备份和编辑 Hadoop 的 yarn-site.xml 配置文件。注意替换为你的学号后4位。
cp /opt/hadoop/etc/hadoop/yarn-site.xml{,.bak}
vim /opt/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>nodea+你学号后4位</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
- 编辑 slaves ,清除原来的所有内容,增加配置 DataNode 节点信息。注意替换为你的学号后4位。
vim /opt/hadoop/etc/hadoop/slaves
nodeb+你学号后4位
nodec+你学号后4位
- 修改 hadoop-env.sh,在第1行加入以下代码。
vim /opt/hadoop/etc/hadoop/hadoop-env.sh
JAVA_HOME=/opt/jdk8
- 把
NodeA节点的 Hadoop /opt/hadoop/etc/hadoop 下所有配置文件发送到NodeB和NodeC。如果上面的配置文件有修改,也需要同步发送到NodeB和NodeC节点。
cd /opt/hadoop/etc/
scp -r hadoop hadoop@nodeb+你学号后4位:/opt/hadoop/etc/
scp -r hadoop hadoop@nodec+你学号后4位:/opt/hadoop/etc/
- 格式化 HDFS。请勿重复执行,因为会导致 datanode 和 namenode 的集群ID不一致,造成HDFS出错。
hdfs namenode -format
- 新建启动和停止 Hadoop 的脚本。
- 创建启动脚本,注意替换为你的学号后4位。
vim /opt/hadoop/sbin/start-hdp.sh
#!/usr/bin/env bash
echo "Start Hadoop by 你的学号后4位"
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
- 创建停止脚本,注意替换为你的学号后4位。
vim /opt/hadoop/sbin/stop-hdp.sh
#!/usr/bin/env bash
echo "Stop Hadoop by 你的学号后4位"
mr-jobhistory-daemon.sh stop historyserver
stop-yarn.sh
stop-dfs.sh
- 重启脚本
vim /opt/hadoop/sbin/restart-hdp.sh
#!/usr/bin/env bash
stop-hdp.sh
start-hdp.sh
- 修改创建的脚本的权限。
cd /opt/hadoop/sbin/
chmod 744 start-hdp.sh stop-hdp.sh restart-hdp.sh
- 使用脚本启动 Hadoop。
start-hdp.sh
【实验验证步骤】
- 在
NodeA输入jps命令,观察是否有以下进程。
NameNode
Jps
ResourceManager
SecondaryNameNode
JobHistoryServer
- 在
NodeB和NodeC分别输入jps命令,观察是否有以下进程。
DataNode
NodeManager
Jps
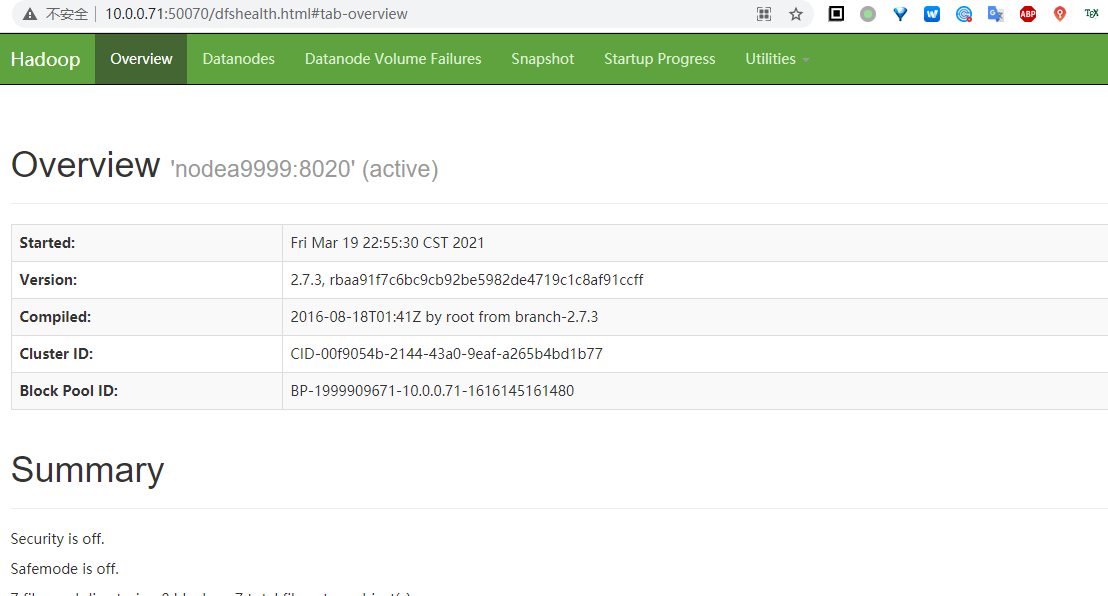
打开宿主机浏览器,访问 HDFS Web界面 http://10.0.0.71:50070/
上传
countryroad.txt到NodeA的/home/hadoop把
countryroad.txt从 CentOS 文件系统上传到 HDFS 文件系统。
hdfs dfs -mkdir /part2
hdfs dfs -put /home/hadoop/countryroad.txt /part2
hdfs dfs -ls /part2
- 运行 Hadoop 自带的 Wordcount 程序,观察输出的内容。
cd $HADOOP_HOME/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /part2/countryroad.txt /output
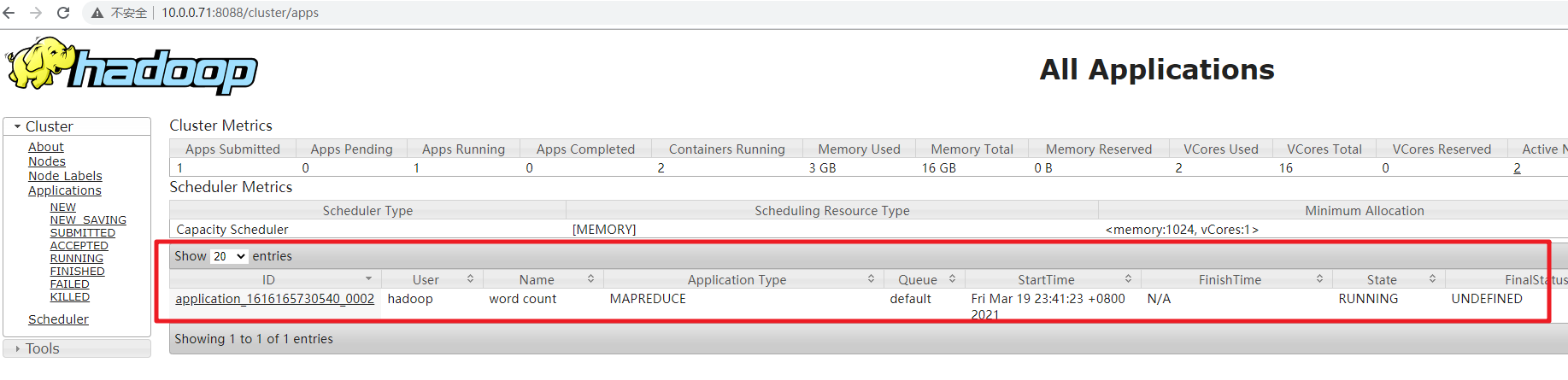
- 程序执行过程中,可以访问 Yarn Web 界面查看任务进展。 http://10.0.0.71:8088/cluster/apps
- 等待程序运行完毕,观察输出的内容
hdfs dfs -cat /output/part-r-00000