【版本】
当前版本号v20240529
| 版本 | 修改说明 |
|---|---|
| v20240529 | 完善JSON 转换 CSV 格式提示,增加了相关的提示 |
| v20240226 | 初始化版本 |
【任务名称】任务3 - 在电影库中查找我的演员合作次数最多的演员及其合作作品。
【任务目的】
- 掌握使用 Hive 进行数据分析
【任务环境】
- Windows 7+
- VirtualBox
- CentOS 7
- Hadoop 3
- JDK 版本:1.8 或以上版本。
- Hive 2.3.8
【任务说明】
Film.json是豆瓣电影的真实电影数据。里面包含了41960部电影数据。其中各个字段解释如下表
| 字段名 | 注释 |
|---|---|
| title | 电影名 |
| year | 上映年份 |
| type | 电影类型 |
| star | 电影评分2-10分 |
| director | 导演 |
| actor | 演员 |
| time | 电影时长 |
| film_page | 电影信息链接 |
【任务要求】
-(1)在表格学生演员分配.xlsx里找到分配给你的演员。
-(2)结合本门课程学过的知识,编写程序(Java程序/MapReduce)对’Film.json’内容进行筛选,筛选出只包含你的演员演过的电影,并转换为 csv 格式。
-(3)把转换后csv文件导入 Hive,使用 SQL 查询和我的演员合作次数最多的前5位演员及其合作最高分的作品(如果同分则优先列出年份较近的,例如2000年上映的A电影和1995年上映的B电影同分,则排序应该为A,B)。需要展示演员姓名,合作次数,以及合作最高分的作品名称和评分。
【任务提示】
【提示1 - Java程序实现 JSON 转换 CSV 格式】
(1) 实验5.1已经提示了如何把 JSON 格式转换为 Java 的对象。这里JSON可以先转换为 Java 对象,再转换为CSV。CSV的格式非常简单,使用分行符表示1行数据,每个单元数据使用英文的逗号,隔开。
(2) 把Film.json的文件放在src/main/resources目录下。
(3) 以下代码是实现把电影库的JSON格式转换为只我的演员参演电影的 CSV 格式数据。
Json2CoActorCsv类参考代码如下:
import com.alibaba.fastjson.JSON;
import java.io.*;
public class Json2CoActorCsv {
//演员姓名
private final static String ACTOR="修改为我的演员的姓名";
private final static String RESOURCE_DIR= new File(Json2CoActorCsv.class.getClassLoader().getResource("Film.json").getPath()).getParent();
public static void main(String[] args) throws IOException {
//获取Film.json的路径
String filmJsonPath= Json2CoActorCsv.class.getClassLoader().getResource("Film.json").getPath();
//读取Film.json
BufferedReader br=new BufferedReader(new FileReader(filmJsonPath));
//写到哪个文件
FileWriter sw=new FileWriter(new File(RESOURCE_DIR,"CoActor.csv"));
//MovieInfo 类可以参考实验1
MovieInfo m=null;
String line;
while((line=br.readLine())!=null){
//Fastjson 把每行的json 字符串转换为对象。
m= JSON.parseObject(line,MovieInfo.class);
//过滤并把每部电影合作的每个演员,都转为包含电影信息1行csv数据
if(m.getActorSet().contains(ACTOR)){
//Film_page 作为电影ID
String mid=m.getFilm_page();
//取出演员的列表
String[] actors=m.getActor().split(",");
for(String ac:actors){
//把电影数据写入csv文件。csv 表头为 ID,电影名称,评分,演员
sw.append(mid+","+m.getTitle()+","+ac+","+m.getStar()+","+m.getYear()+"\n");
}
}
}
sw.close();
br.close();
}
}
MovieInfo类代码可以参考任务2,其中 getActorSet() 方法是返回电影的演员列表集合(Set)。
public Set<String> getActorSet(){
Set<String> set=new HashSet<>();
if(actor!=null){
String[] as=actor.split(",");
String trimActorName=null;
for(String a:as){
trimActorName=a.trim();
if(!"".equals(trimActorName)){
set.add(trimActorName);
}
}
}
return set;
}
(4) 为了方便我们后续分析,可以考虑转换1行 JSON 为多行的 CSV 数据,这样在统计演员合作次数的时候会更容易统计。例如以下 JSON 数据,可以考虑转换为示例中的 CSV 格式。
{"_id":{"$oid":"5ad930de6afaf81ac48844a0"},"title":"重庆森林 重慶森林","year":"1994","type":"剧情,爱情","star":8.7,"director":"王家卫","actor":"林青霞,金城武,梁朝伟,王菲,周嘉玲","pp":358053,"time":102,"film_page":"https://movie.douban.com/subject/1291999/"}
- 转换以后,只需要包含film_page、title、actor、star、year 这几列。这时候统计演员的合作次数只需要统计每个演员出现的次数就可以了。
https://movie.douban.com/subject/1291999/,重庆森林 重慶森林,林青霞,8.7,1994
https://movie.douban.com/subject/1291999/,重庆森林 重慶森林,金城武,8.7,1994
https://movie.douban.com/subject/1291999/,重庆森林 重慶森林,梁朝伟,8.7,1994
https://movie.douban.com/subject/1291999/,重庆森林 重慶森林,王菲,8.7,1994
https://movie.douban.com/subject/1291999/,重庆森林 重慶森林,周嘉玲,8.7,1994
【提示2 - 使用 group by 分组统计次数】
(1) 复制以下 SQL 语句到输入框内运行,查看 film_actor 表的数据。
select * from film_actor
(2) 以下是使用group by语句统计每部电影演员数量。
select tit as `电影名`,count(actor) as `演员数量` from film_actor group by tit
group by 语句一般放在 SQL语句的 where 后面,group by后面一般会加上列的名称,他通常会配合聚合函数来进行分组查询统计。
group by 后面的列,一定要出现在 select 语句后面。

以上面SQL语句为例,group by 后面的 tit列,指的是把tit列有相同的值分为一组,count() 函数只会统计组内的数量。
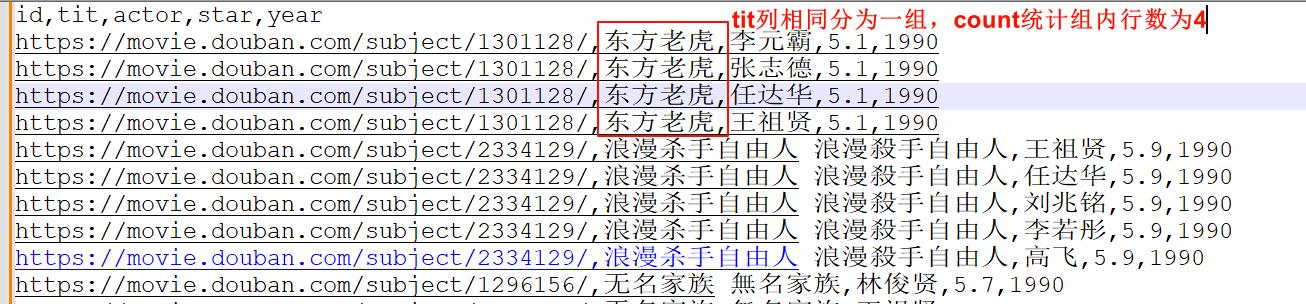
你能根据以上的提示,统计所有演员出现的次数吗?
【提示3 - 使用排名函数 rank 】
rank 函数可以对查询结果按照某种顺序来进行排名,而且会考虑到排名并列的情况。
(1) 以下表ACTOR_COUNT为例,这是一个演员合作次数表,其中N表示次数。
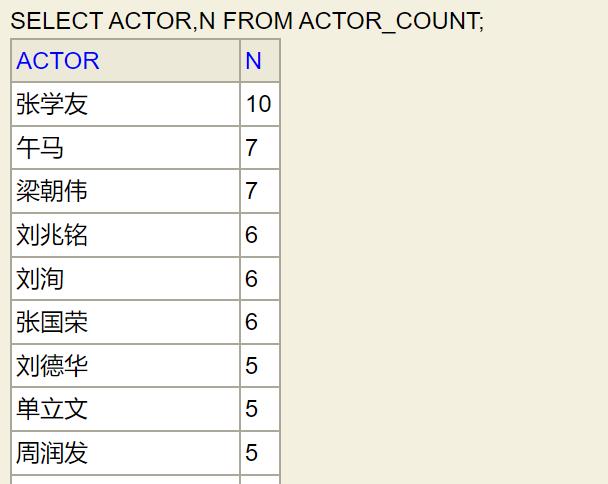
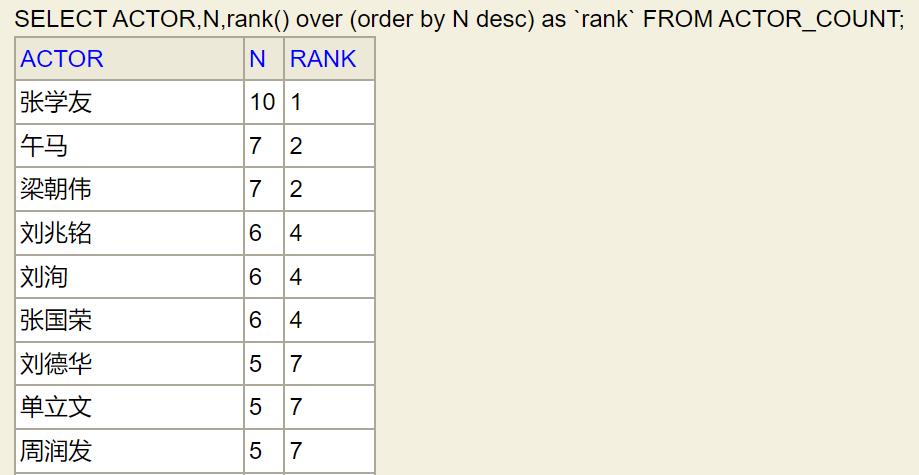
(2) 如果我要对演员合作次数进行排名,可以执行以下SQL。
SELECT ACTOR,N,rank() over (order by N desc) as `rank` FROM ACTOR_COUNT
其中
rank() over (order by N desc)表示的是按照N列的值进行降序排列,并依次给出排名值。
【提示4 - 使用排名函数 row_number】
row_number 函数可以对查询结果按照某种顺序来进行排名,甚至可以支持分组排名,但是不支持排名并列的情况。
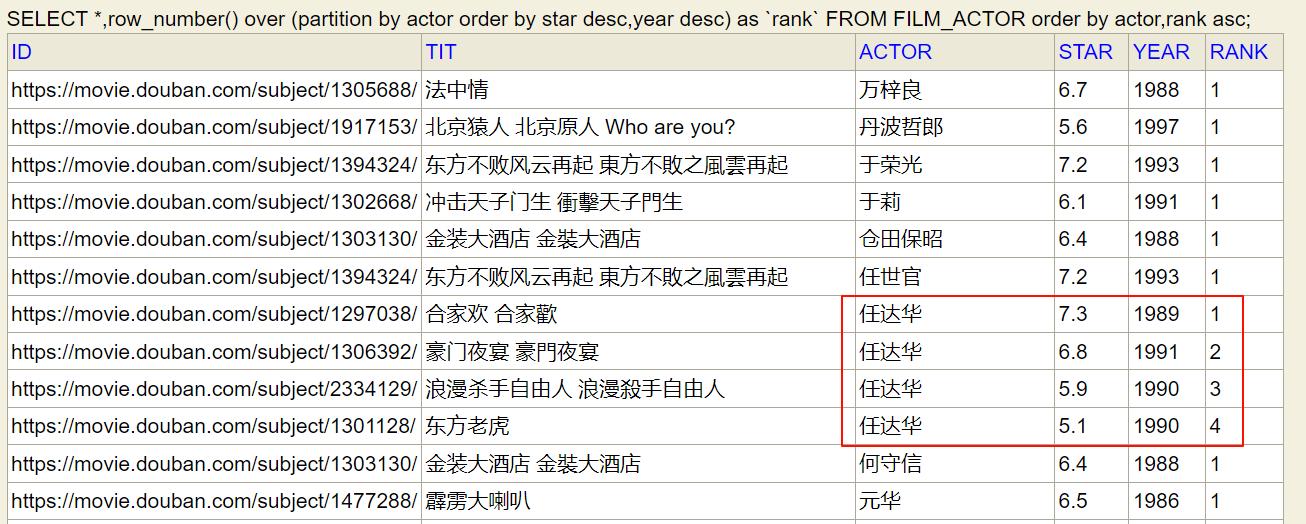
(1) 以下表FILM_ACTOR为例,这是电影与演员一一对应表。其中 star 表示评分,year 表示上映年份。
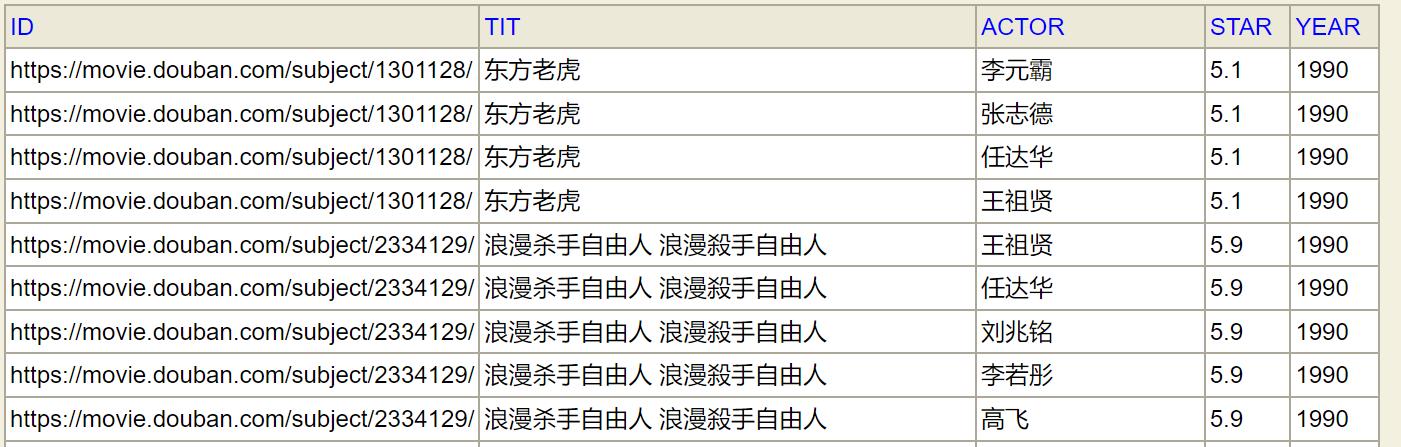
(2) 如果我要对其中各个演员自己作品评分排名,可以执行以下 SQL 语句。其中 RANK 则是演员所有电影的评分排名。
SELECT *,row_number() over (partition by actor order by star desc,year desc) as `rank` FROM FILM_ACTOR order by actor,rank asc
其中
partition by actor指的是相同的演员分为一组单独进行排名;order by star desc,year desc指的是按照评分降序排列,同分情况下按年份降序排列。
【提示5 - 创建视图】
视图包含行和列,我们可以把它当成一个表来使用。对于某些复杂的查询SQL语句,我们可以把他的查询结果保存为一个视图,方便我们后续进行反复的查询。
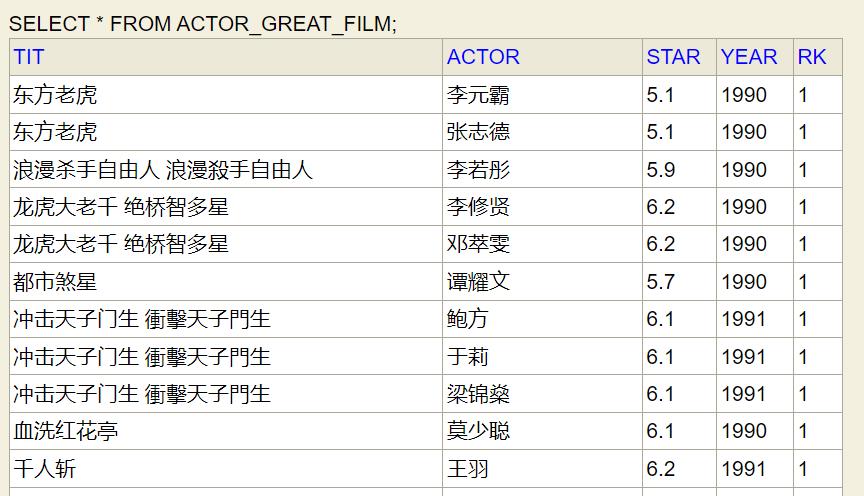
(1) 以下表FILM_ACTOR为例,这是电影与演员一一对应表。其中 star 表示评分,year 表示上映年份。
(2) 如果我要对其中各个演员自己作品评分排名,并且把该演员最好的作品保存为一个视图,可以执行以下 SQL 语句。
create view actor_great_film as
select * from (
select tit,actor,star,year,row_number() over(partition by actor order by star desc,year desc) as rk from film_actor
) ab where rk=1;
其中
actor_great_film是视图的名称,create view 视图名 as后面生成视图的查询SQL语句。
【提示6 - 连接表】
表的连接,指的是可以通过SQL语句把多个表通过关联字段,组合成为一个查询结果。常用的连接包括内连接、左外连接。
(1)以下2个表,其中cla是班级表,stu是学生表。2个表通过班级编号cid列进行关联。

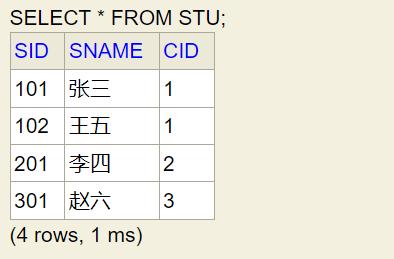
(2)在以下输入框分别执行以下2个SQL语句,查看内连接和左连接的查询结果有什么区别。
- 内连接
select * from stu a inner join cla b on a.cid=b.cid
- 外连接
select * from stu a left join cla b on a.cid=b.cid
