【版本】
当前版本号v20240529
| 版本 | 修改说明 |
|---|---|
| v20240529 | 添加常见问题 |
| v20240226 | 初始化版本 |
【任务名称】任务2 - 在电影库中查找我的演员评分最高的5部电影
【任务目的】
- 掌握 MapReduce 的 Mapper 编写
- 掌握 MapReduce 序列化的使用
- 掌握 MapReduce 的排序
【任务环境】
- Windows 7+
- VirtualBox
- CentOS 7
- Hadoop 3
- JDK 版本:1.8 或以上版本。
- Hive 2.3.8
【任务说明】
- 软件资源
Film.json是豆瓣电影的真实电影数据。里面包含了41960部电影数据。其中各个字段解释如下表
| 字段名 | 注释 |
|---|---|
| title | 电影名 |
| year | 上映年份 |
| type | 电影类型 |
| star | 电影评分2-10分 |
| director | 导演 |
| actor | 演员 |
| time | 电影时长 |
| film_page | 电影信息链接 |
【任务要求】
(1)在表格
学生演员分配.xlsx里找到分配给你的演员。(2)结合本门课程学过的知识,编写 MapReduce 程序,按评分从高到低排序该演员参演电影(如果同分则优先列出年份较近的,例如2000年上映的A电影和1995年上映的B电影同分,则排序应该为A,B),找到评分最高的前5部电影的名称,上映年份和评分。
【任务提示】
【提示1 序列化和排序】
使用 IDEA 打开 hdp-training-exp1 项目。
运行
src/test/java/hadoop9999/training/exp1/test/HadoopSerializationTest.java单元测试。此单元测试展示了在 MapReduce 中,键值对中的对象序列化的代码。如果只需要对对象进行序列化,只需要实现
org.apache.hadoop.io.Writable接口。如果同时要对对象进行序列化,同时也需要对对象进行排序,需要实现
org.apache.hadoop.io.WritableComparable接口。MapReduce 的排序主要是利用了在 Shuffle 阶段对键值对中的键(Key)进行的排序。
【提示2 如何对把 JSON 转换为 Java 对象】
使用 IDEA 打开 hdp-training-exp1 项目。
运行
src/test/java/hadoop9999/training/exp1/test/JsonParseTest.java单元测试。此单元测试展示了如果把 JSON 的字符串转换为 Java 对象。
【提示3 如何对 Mapper 进行测试】
使用 IDEA 打开 hdp-training-exp1 项目。
运行
src/test/java/hadoop9999/training/exp1/test/MapperTest.java单元测试。此单元测试展示了如何对 MapReduce 中的 Mapper 进行测试。
【常见问题】
- 运行 MapReduce 程序提示
java.lang.ClassNotFoundException找不到com.alibaba.fastjson.JSON。
答:这是因为运行的 MapReduce 程序没有找到 fastjson-1.2.62.jar包,需要把此 jar 包上传到 HDFS(注意是HDFS,不是虚拟机),例如/lib/fastjson-1.2.62.jar,然后在 MapReduce 的 Main 程序中,调用Job类对象的addFileToClassPath方法,参考以下代码,引用到此 jar 包。
job.addFileToClassPath(new Path("/lib/fastjson-1.2.62.jar"));
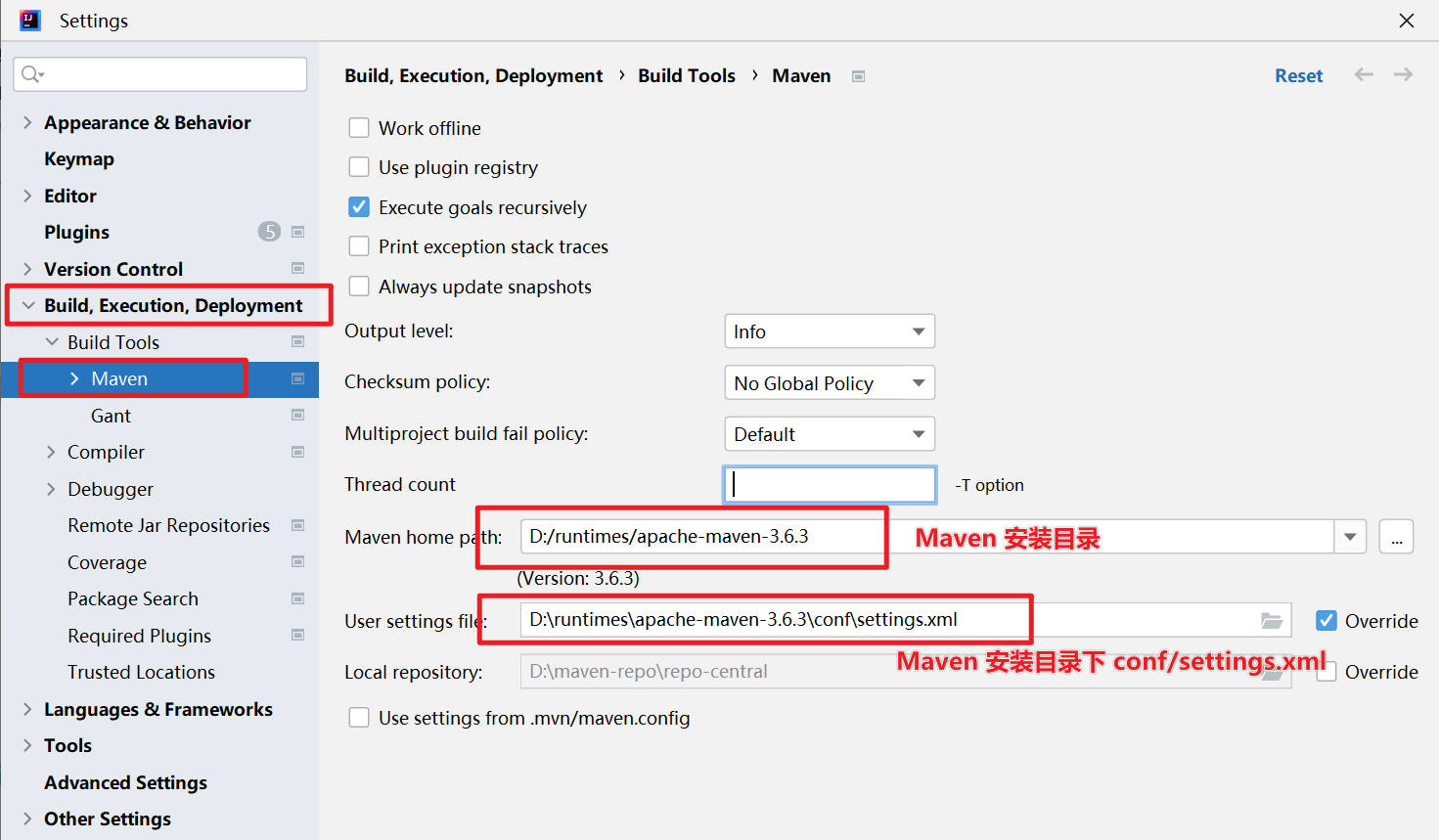
- 项目无法编译,pom.xml 报错,无法引入依赖的 jar 包。
答:这可能是 Maven 没有配置正确导致的。检查 IDEA 的 Maven 配置。菜单File->Settings,Build,Execution,Deployment->Build Tools->Maven,进行配置。