【版本】
当前版本号v20210603-1
| 版本 | 修改说明 |
|---|---|
| v20210603-1 | 修正hostname的错误 |
| v20210603 | 补充个别shell命令,修正start-zk.sh脚本错误 |
| v20210601 | 初始化版本 |
实验9.1 - 部署 ZooKeeper 集群模式
【实验目的】
- 部署 ZooKeeper 集群模式
【实验环境】
- Windows 7 以上64位操作系统
- JDK8
- VMWare Workstation Pro
- Hadoop 2.7.3
- CentOS 7
【实验资源】
- Hadoop 2.X
- ZooKeeper 3.X
链接:https://pan.baidu.com/s/1MoQ0iU0Qb1o8_o5JV6X6iw
提取码:3rno
【实验内容】
- 部署 ZooKeeper 集群模式
【实验步骤】
- 在NodeA、NodeB、NodeC三个节点分别运行以下语句,注意提升为root权限执行。
- 分别创建 ZooKeeper 的安装目录、数据存放目录和配置文件存放目录。
su
mkdir /opt/zookeeper
mkdir /opt/zookeeper_data
mkdir /opt/zookeeper_config
chown hadoop:wheel /opt/zookeeper
chown hadoop:wheel /opt/zookeeper_data
chown hadoop:wheel /opt/zookeeper_config
- 提升 root 用户权限执行以下语句,加入 ZooKeeper 环境变量。
su
echo "export ZK_HOME=/opt/zookeeper
export PATH=\$ZK_HOME/bin:\$PATH:." >>/etc/profile
- 切换会 hadoop 用户
su hadoop
- 使环境变量生效。
source /etc/profile
- 使用 hadoop 登录NodeA节点。
su hadoop
上传 ZooKeeper 安装包
apache-zookeeper-3.5.5-bin.tar.gz到 NodeA 节点/home/hadoop目录。解压
apache-zookeeper-3.5.5-bin.tar.gz到/home/hadoop目录。把解压以后的目录移到安装目录
sudo mv ~/apache-zookeeper-3.5.5-bin/* /opt/zookeeper
- 编辑 ZooKeeper 脚本加入JAVA_HOME 配置
cd $ZK_HOME/bin
vim zkServer.sh
- 在第2行加入以下代码。
export JAVA_HOME=/opt/jdk8
- 同步 NodeA 节点的 ZooKeeper 安装目录内容到 NodeB 和 NodeC。注意替换为你的学号后4位。
rsync -r /opt/zookeeper nodeb你的学号后4位:/opt
rsync -r /opt/zookeeper nodec你的学号后4位:/opt
rsync 是文件同步命令,可以用于本机和远程之间的文件同步 如果没有安装,可以使用 yum install rsync 安装
- 以下需要在 NodeA、NodeB、NodeC 3个节点分别配置。
- (1)新增 ZooKeeper 的配置文件。
cd /opt/zookeeper/conf
cp zoo_sample.cfg /opt/zookeeper_config/zoo.cfg
- (2)修改 zoo.cfg 配置。
vim /opt/zookeeper_config/zoo.cfg
- (3)在约第12行修改数据保存目录
dataDir=/opt/zookeeper_data
- (4)在文件末尾加入各个节点的配置。注意替换为你的学号后4位。注意替换你的学号。
server.1=nodea你的学号后4位:2888:3888
server.2=nodeb你的学号后4位:2888:3888
server.3=nodec你的学号后4位:2888:3888
- (5)在文件末尾加入各个节点的绑定的地址。
clientPortAddress的值在NodeA为nodea你学号后4位,NodeB 为nodeb你学号后4位,NodeC 为nodec你学号后4位。
clientPortAddress=配置为相应节点的Hostname
- (6)创建软连接,把配置文件指向 ZooKeeper 的默认配置目录。
ln -s /opt/zookeeper_config/zoo.cfg /opt/zookeeper/conf/zoo.cfg
- 以下需要在 NodeA、NodeB、NodeC 3个节点分别配置。配置 ZooKeeper 的 ID。
mkdir /opt/zookeeper_data
- NodeA输入1,NodeB输入2,NodeC输入3。
vim /opt/zookeeper_data/myid
- 编写 ZooKeeper 集群启动脚本。注意替换你的学号。
vim $ZK_HOME/bin/start-zk.sh
输入以下内容
#!/usr/bin/env bash
echo "Start NodeA ZooKeeper"
zkServer.sh start
echo "Start NodeB ZooKeeper"
ssh nodeb你学号后4位 "/opt/zookeeper/bin/zkServer.sh start"
echo "Start NodeC ZooKeeper"
ssh nodec你学号后4位 "/opt/zookeeper/bin/zkServer.sh start"
- 编写 ZooKeeper 集群关闭脚本。注意替换你的学号。
vim $ZK_HOME/bin/stop-zk.sh
输入以下内容
#!/usr/bin/env bash
echo "Stop NodeA ZooKeeper"
zkServer.sh stop
echo "Stop NodeB ZooKeeper"
ssh nodeb你学号后4位 "/opt/zookeeper/bin/zkServer.sh stop"
echo "Stop NodeC ZooKeeper"
ssh nodec你学号后4位 "/opt/zookeeper/bin/zkServer.sh stop"
- 编写 ZooKeeper 集群重启脚本。注意替换你的学号。
vim $ZK_HOME/bin/restart-zk.sh
输入以下内容
#!/usr/bin/env bash
echo "Restart NodeA ZooKeeper"
zkServer.sh restart
echo "Restart NodeB ZooKeeper"
ssh nodeb你学号后4位 "/opt/zookeeper/bin/zkServer.sh restart"
echo "Restart NodeC ZooKeeper"
ssh nodec你学号后4位 "/opt/zookeeper/bin/zkServer.sh restart"
- 修改创建的脚本的权限。
chmod 755 $ZK_HOME/bin/start-zk.sh
chmod 755 $ZK_HOME/bin/stop-zk.sh
chmod 755 $ZK_HOME/bin/restart-zk.sh
- 尝试使用以上创建的脚本,启动 ZooKeeper 集群。
start-zk.sh
【实验验证步骤】
- 在 NodeA、NodeB 和 NodeC 3个节点分别输入以下命令,查看 ZooKeeper 的 Mode。
zkServer.sh status
- 以下为正常的输出例子,其中Mode 有可能为 follower 或 leader:
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: nodec你学号后4位.
Mode: follower
- 使用
jps命令查看每个节点是否存在以下进程
QuorumPeerMain
实验9.2 - 使用 ZooKeeper Shell 命令访问 ZooKeeper 集群
【实验目的】
- 掌握 ZooKeeper Shell 命令
【实验环境】
- Windows 7 以上64位操作系统
- JDK8
- VMWare Workstation Pro
- Hadoop 2.7.3
- CentOS 7
【实验资源】
- Hadoop 2.X
- ZooKeeper 3.X
链接:https://pan.baidu.com/s/1MoQ0iU0Qb1o8_o5JV6X6iw
提取码:3rno
【实验内容】
- 按要求使用 ZooKeeper Shell 命令访问 ZooKeeper 集群
【实验步骤】
- 在 NodeA 启动 ZooKeeper,通过 ZooKeeper Shell 访问 ZooKeeper。注意替换你的学号。
start-zk.sh
zkCli.sh -server nodea你学号后4位:2181
- 连接成功后,查询有哪些命令。输入如下命令。
help
- 创建节点及子节点。
create /root1 data1
create /root2 data2
create /root1/child1 cdata1
create /root1/child2 cdata2
- 创建临时节点。
create -e /root4 data4
- 创建顺序节点。
create -s /root3 data3
- 查询某个节点下有哪些子节点。
ls /
ls /root1
- 查询某个节点下有哪些子节点带属性信息。
ls2 /
- 更新某个节点的值。
set /root1 newdata1
- 获取节点的状态信息。
stat /root1
- 读取某个节点。
get /root1
- 同步某个节点。
sync /root1
- 删除某个节点。
delete /root1/child1
- 递归删除某个节点。
rmr /root1
- 设置配额(下面限制子节点数量)。
setquota -n 4 /root2
- 删除配额。
delquota /root2
- 设置配额(下面限制数据长度)。
setquota -b 400 /root2
- 显示配额。
listquota /root2
- 关闭当前连接,可用 connect 再次连接,不会退出客户端。
close
- 连接服务器。
connect
- 关闭连接并退出连接客户端。
quit
实验9.3 - 使用 ZooInspector 客户端访问 ZooKeeper 集群
【实验目的】
- 掌握 ZooInspector 的使用
【实验环境】
- Windows 7 以上64位操作系统
- JDK8
- Hadoop 3
- CentOS 7
【实验资源】
- ZooKeeper 3.X
链接:https://pan.baidu.com/s/1MoQ0iU0Qb1o8_o5JV6X6iw
提取码:3rno
【实验内容】
- 按要求使用 ZooInspector 客户端访问 ZooKeeper 集群
【实验步骤】
确保你电脑的系统安装了 JDK8 或以上。下载 ZooInspector.zip 工具包并解压。执行 run.bat 启动 ZooInspector。
在 NodeA 启动 ZooKeeper 集群。
start-zk.sh
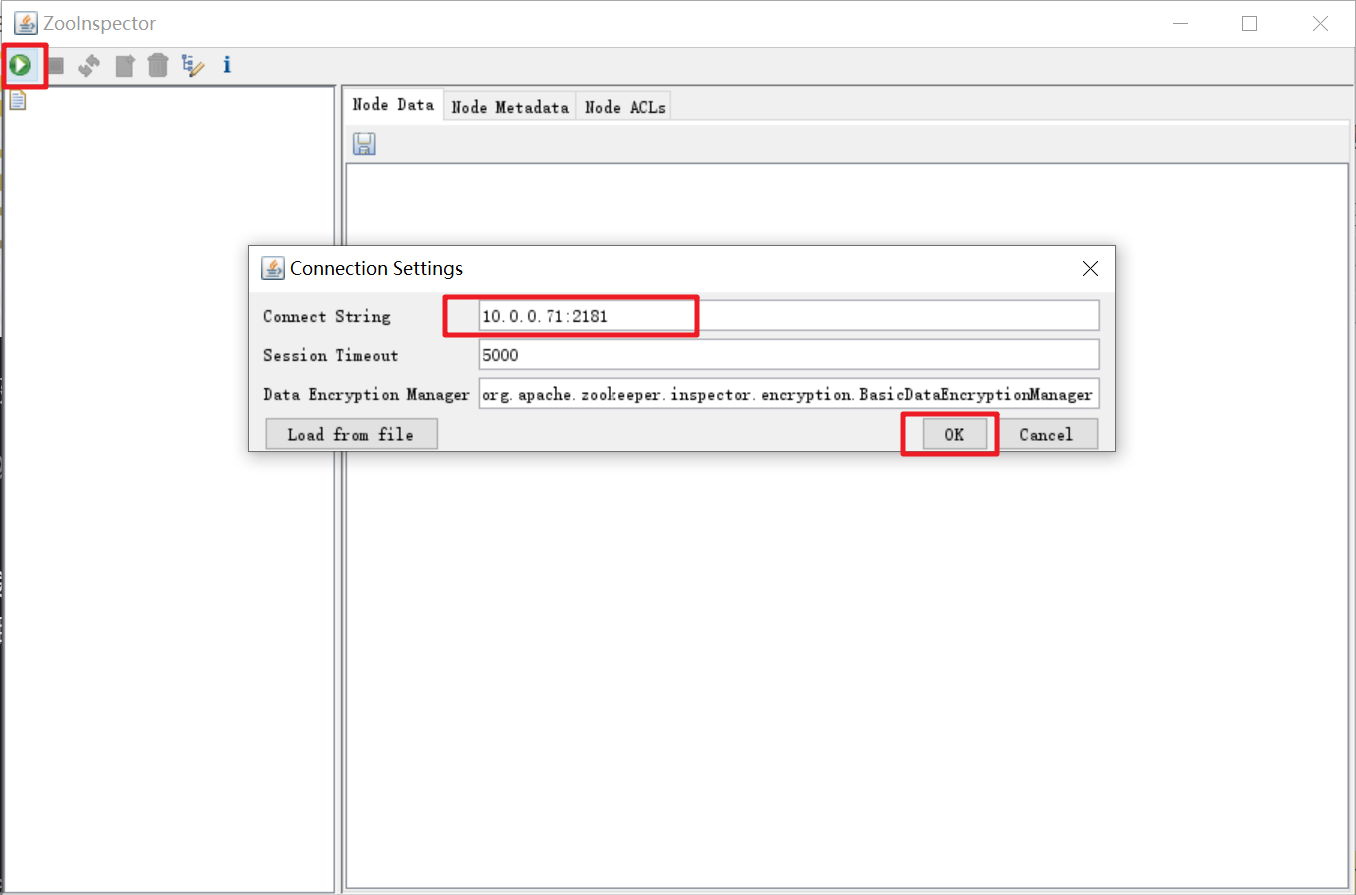
使用 ZooInspector 连接 NodeA 节点。
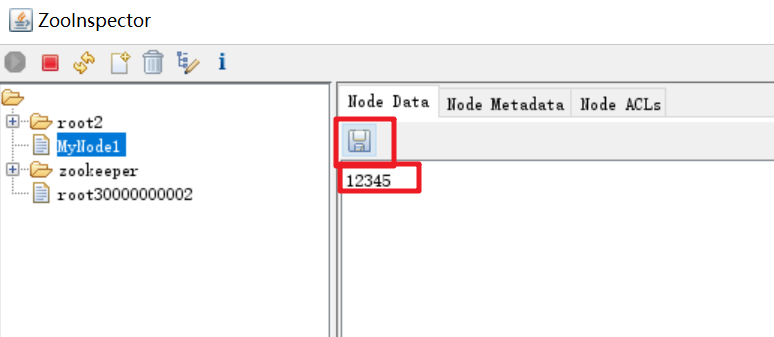
创建一个节点
/MyNode1。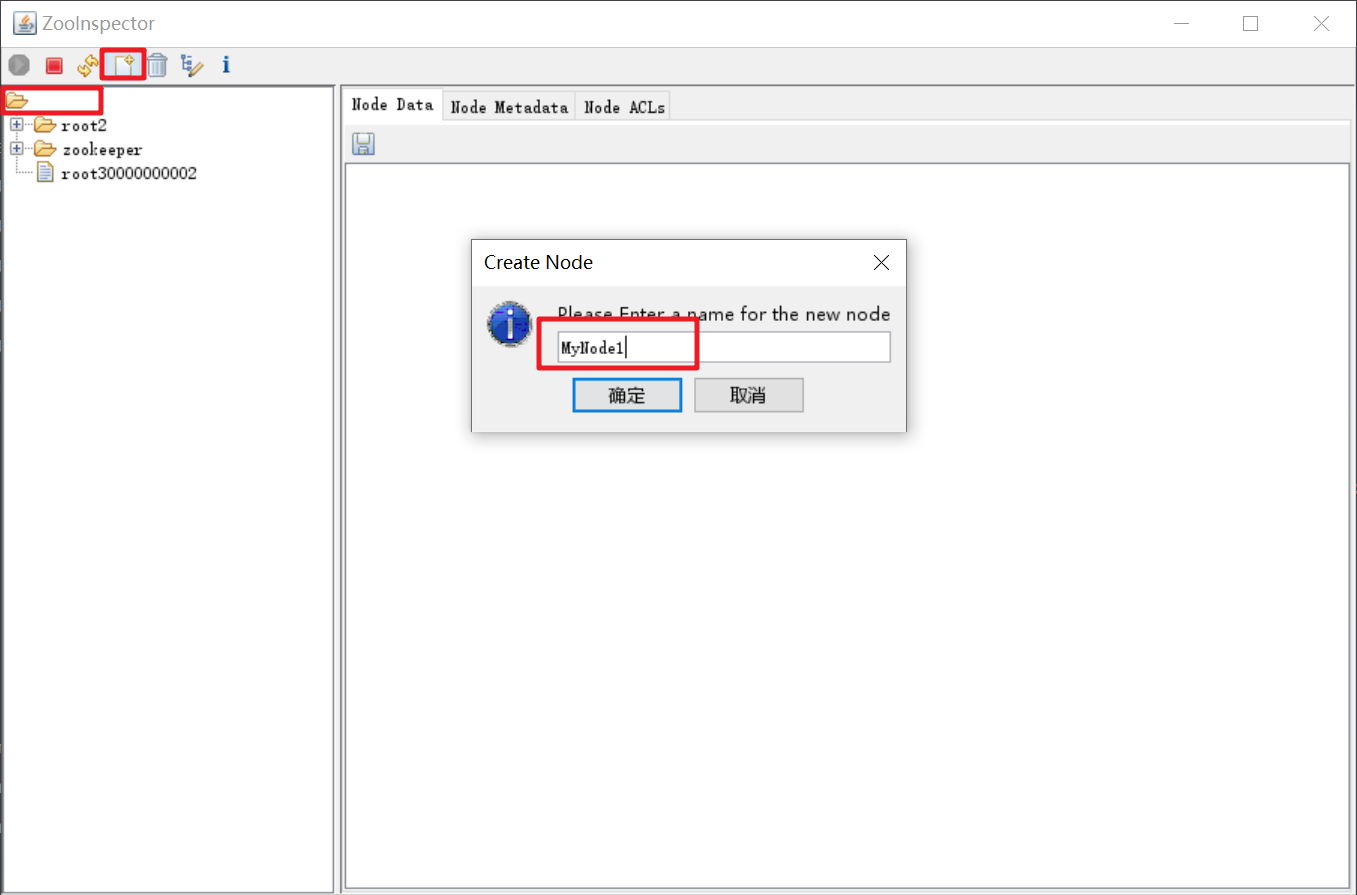
在节点
/MyNode1创建一个 Watch 进行监视。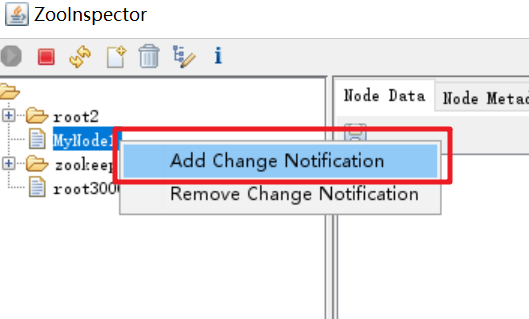
修改节点
/MyNode1的内容,观察时候能够获得通知。