【版本】
当前版本号v20220320
| 版本 | 修改说明 |
|---|---|
| v20220320 | 增加了时间同步 |
| v20220318 | 优化部分步骤和说明 |
| v20220119 | 重新梳理结果,增加专业术语的解析 |
| v20210630 | 初始化版本 |
【实验名称】
Hadoop Part 1 - 模板机制作
【实验目的】
- 掌握搭建 CentOS 模板镜像
- 熟练掌握 Linux命令(vi、tar、mv等等)的使用
- 掌握 VirtualBox、FinalShell 等客户端的使用
【实验环境】
- 内存:至少4G
- 硬盘:至少空余40G
- 操作系统: 64位 Windows系统。
- 虚拟机操作系统:CentOS 7.9
【实验资源】
- FinalShell
- CentOS 7.9系统镜像
- VirtualBox 6.5
- Hadoop 3 安装包
链接:https://pan.baidu.com/s/1MoQ0iU0Qb1o8_o5JV6X6iw
提取码:3rno
【实验内容】
- 完成 Virtualbox 的安装
- 完成 CentOS 系统的安装和配置
- 完成 FinalShell 的安装
- 完成 Hadoop 的解压
【实验步骤】
安装 VirtualBox 和 FinalShell
安装 VirtualBox 6,过程略。如果之前有安装旧版本的 VirtualBox,请先卸载。
安装 FinalShell,过程略。
VirtualBox 新建虚拟机
启动 VirtualBox,点击“新建”,新建1台虚拟机。

类型选择 Linux,版本选择 Red Hat(64-bit)。
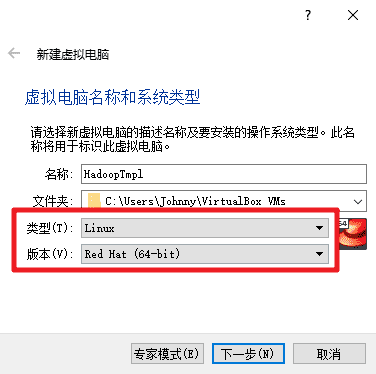
分配 1024M 内存。
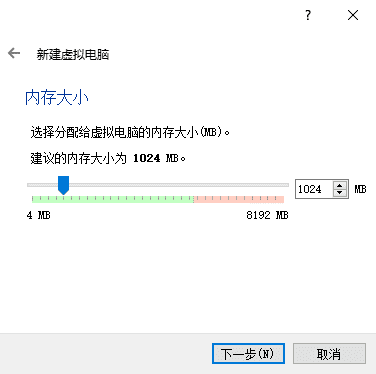
创建虚拟磁盘。
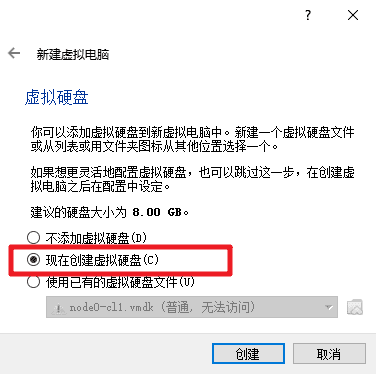
磁盘映像选择 VDI。
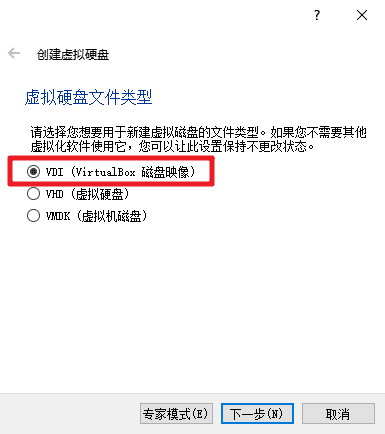
磁盘选择“动态分配”。
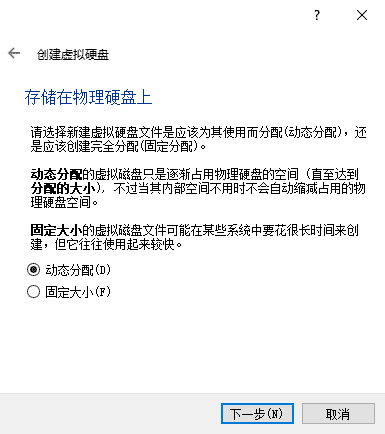
磁盘分配最大容量 30GB。点击“创建”。
设置虚拟机。
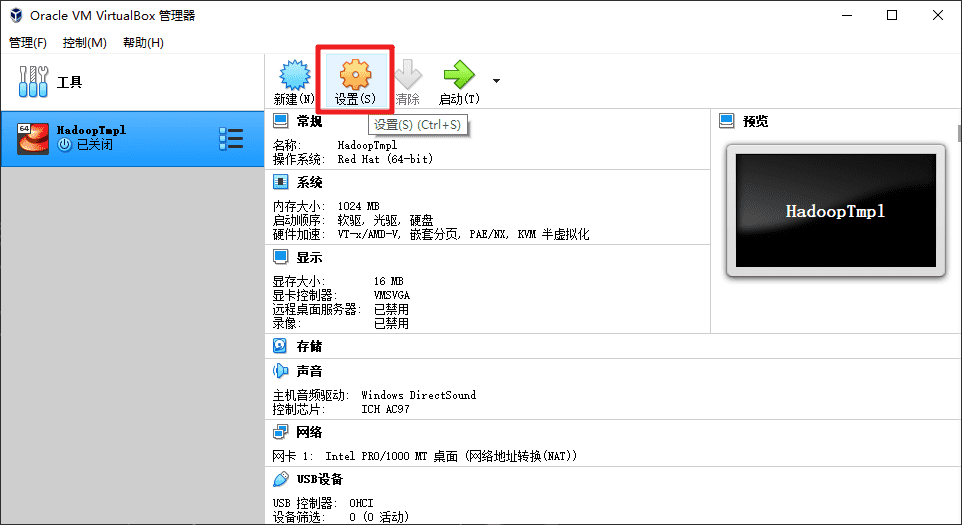
加载 CentOS 的安装镜像。
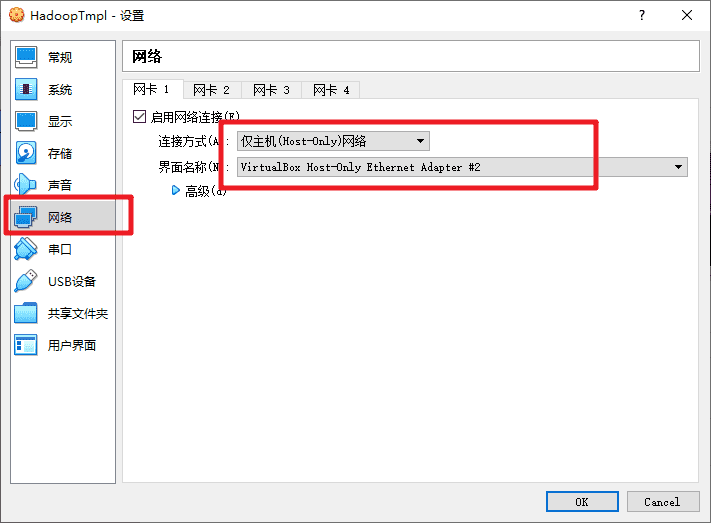
连接方式选择“仅主机(Host-Only)网络”,网卡选择“VirtualBox Host-Only Ethernet Adapter #2”。
设置虚拟机时间与宿主机时间同步
- 在 Windows 的命令行窗口输入以下命令。
- 修改以下
D:\"Program Files (x86)"\Oracle\VirtualBox路径为你的 Virtualbox 安装路径。
cd d:
cd D:\"Program Files (x86)"\Oracle\VirtualBox
如果你安装在d盘,需要先输入
d:切换到D盘,再运行 cd 命令 VirtualBox 的安装路径可以通过桌面的 VirtualBox 快捷方式打开
- CMD 执行以下命令启用与宿主机时间同步,以下"Tmpl"需要修改为你的虚拟机名称。
VBoxManage setextradata "Tmpl" "VBoxInternal/Devices/VMMDev/0/Config/GetHostTimeDisabled" "0"
安装CentOS 7
启动“HadoopTmpl”虚拟机。
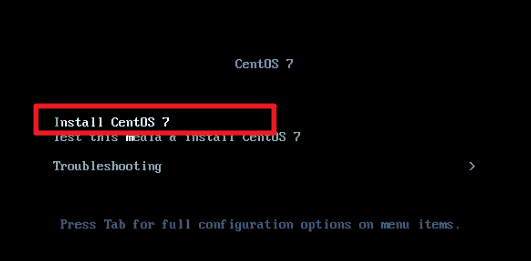
选择“Install CentOS 7”,进行 CentOS 安装。
虚拟机安装语言选择默认英语。
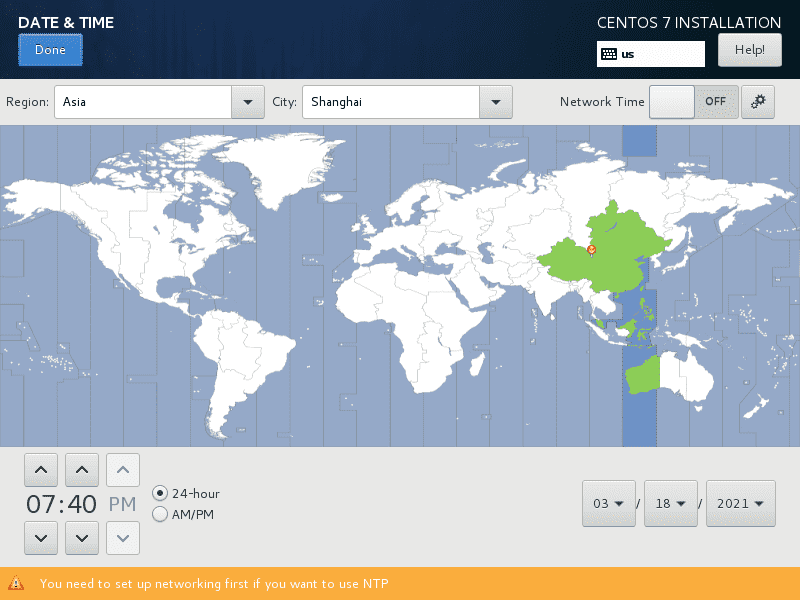
时区选择东8区,注意调整时间为你当前安装的实际时间。
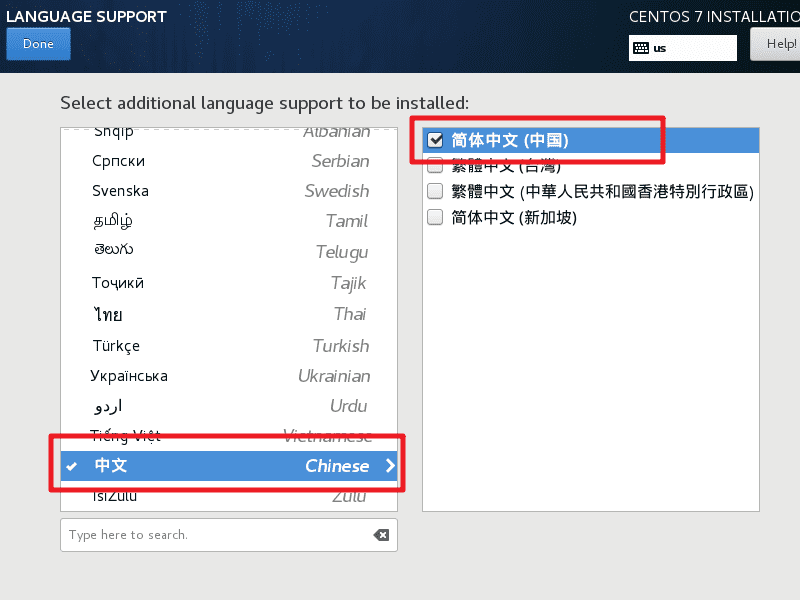
语言支持勾选中文。

网口设置,启用网口,并设置 Host Name 为
hadooptmpl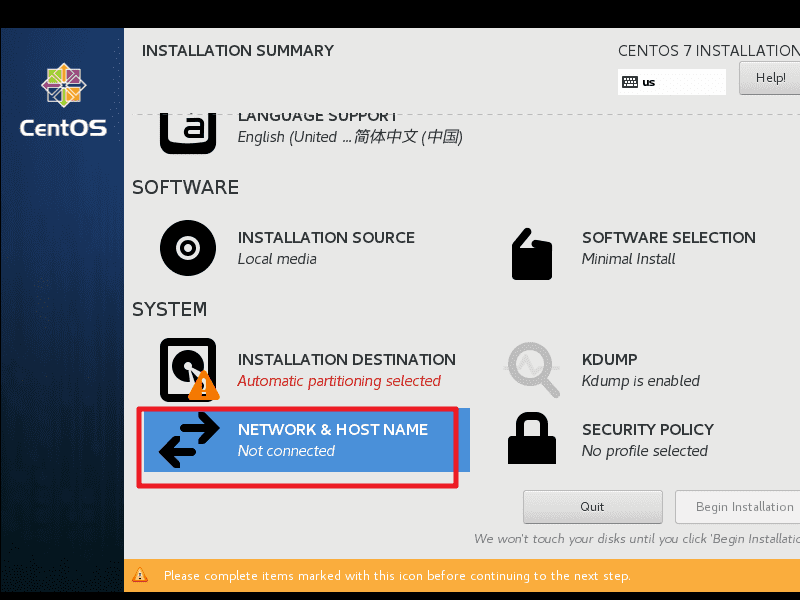
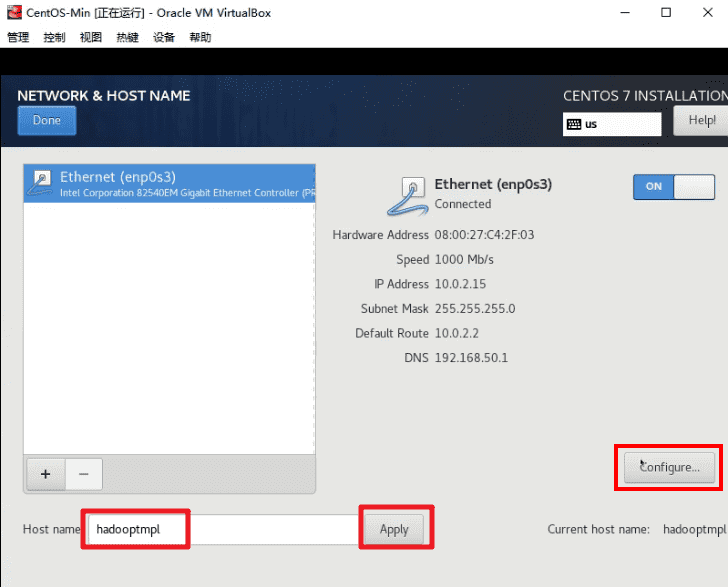
设置网口信息。
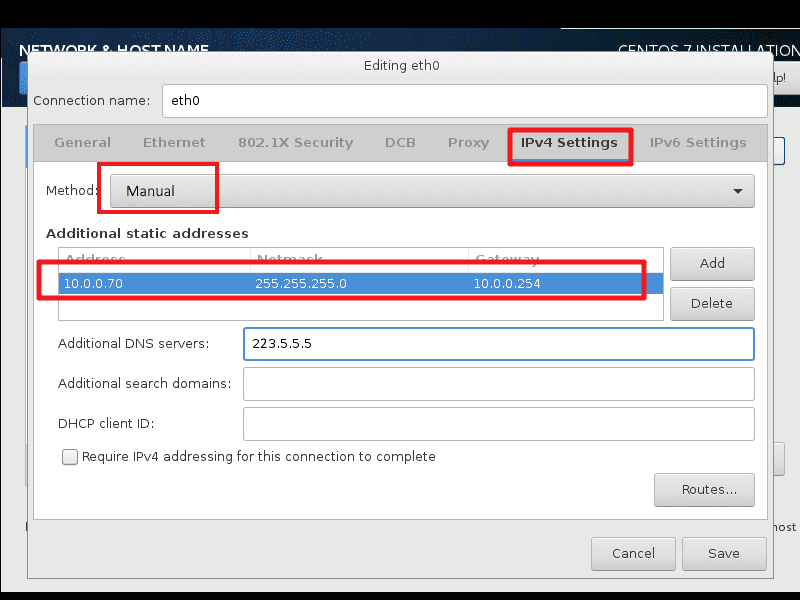
地址:10.0.0.70
掩码:24
网关:10.0.0.254
DNS:223.5.5.5
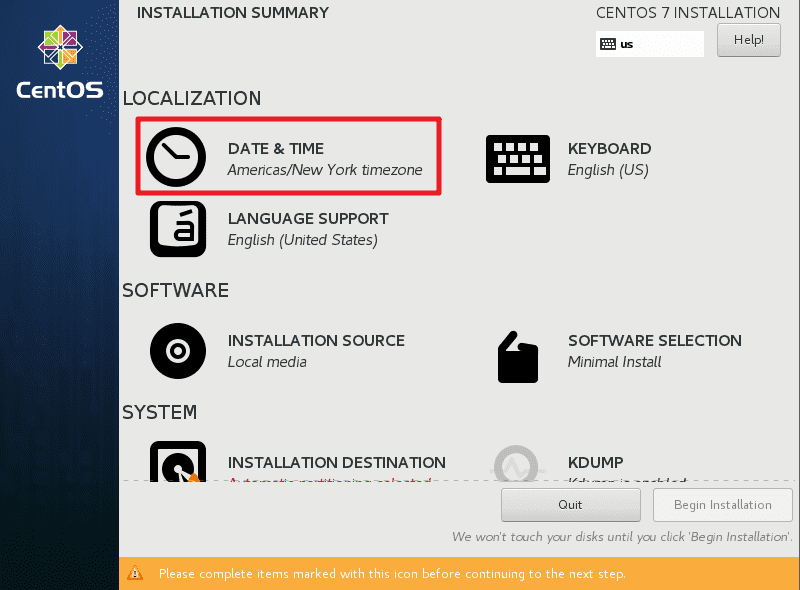
回到主界面,进入软件选择界面,选择最小化安装“Minima Install”。
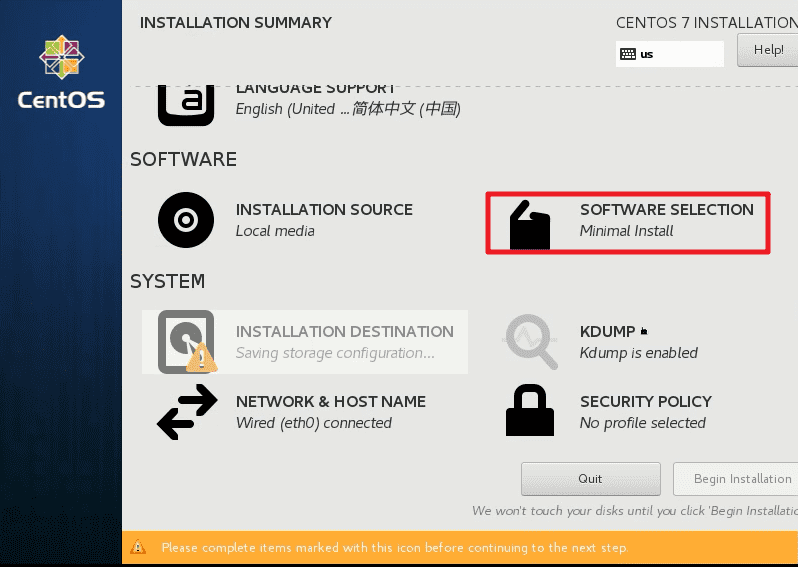
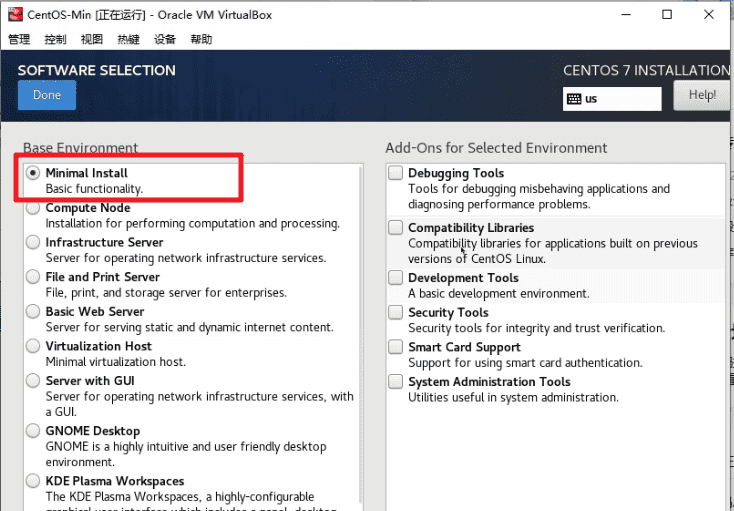
回到主界面,进入系统安装位置菜单。
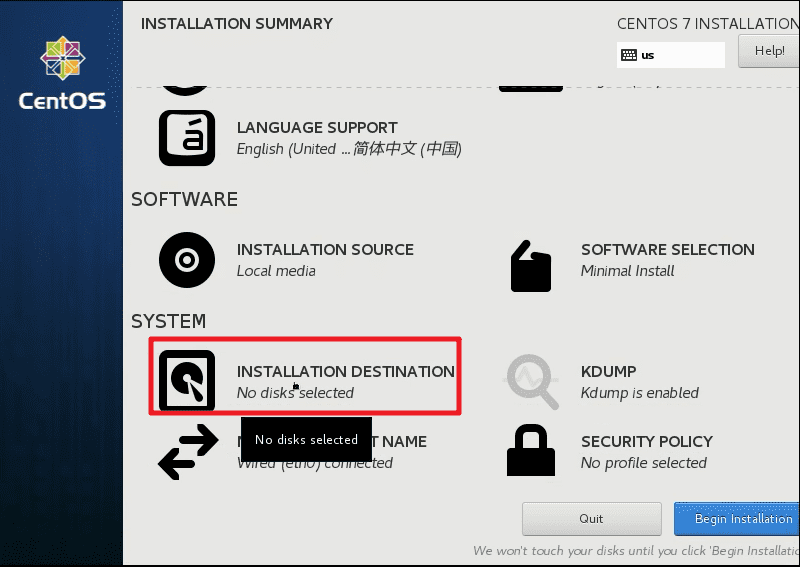
选择手动分区。
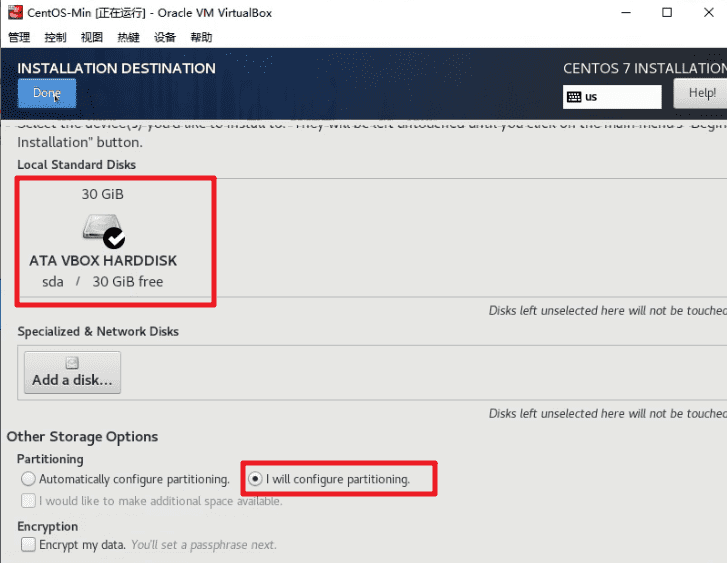
选择标准分区格式
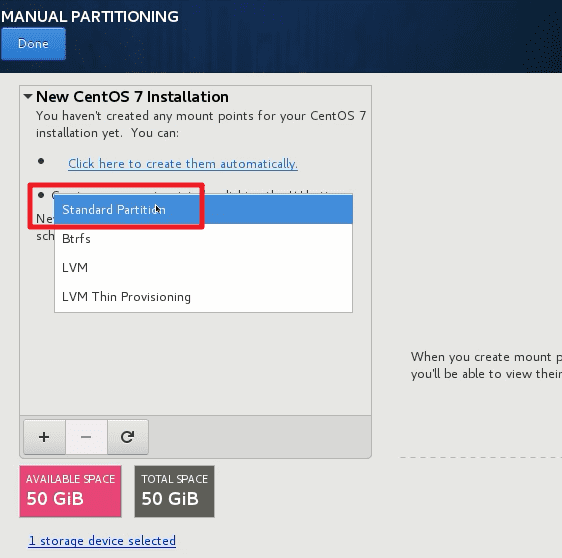
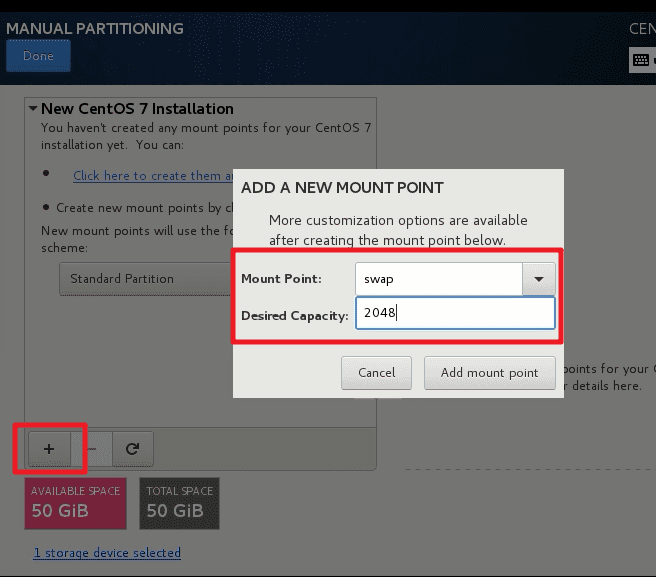
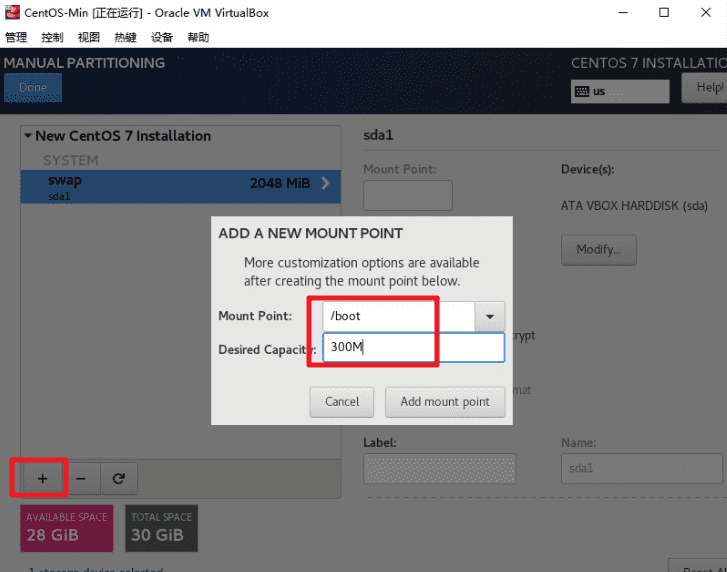
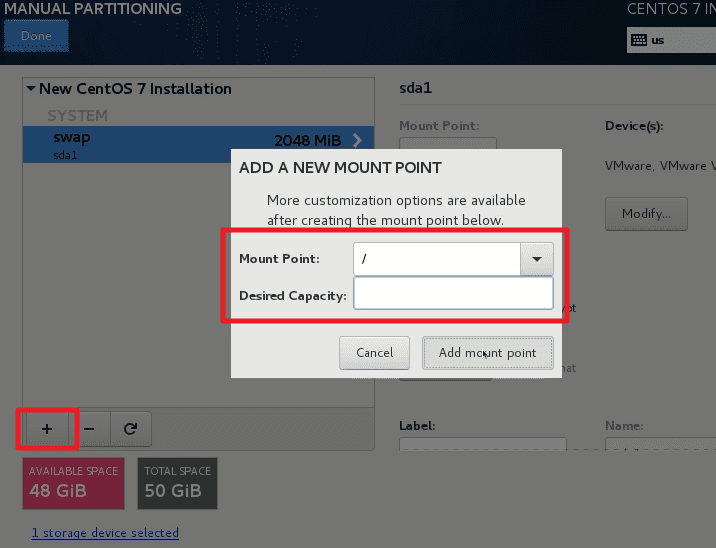
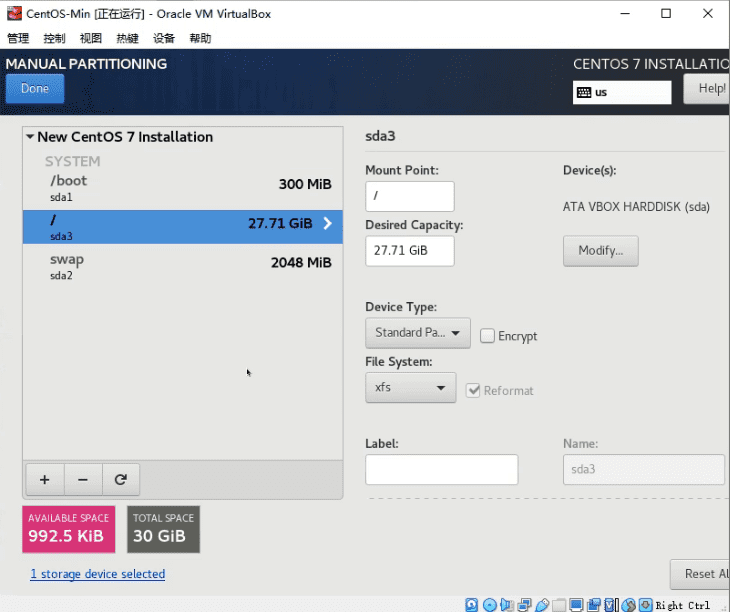
新建3个分区(Partition)
swap分区:2048M
/boot 分区:300M
/ 根分区:剩余所有空间
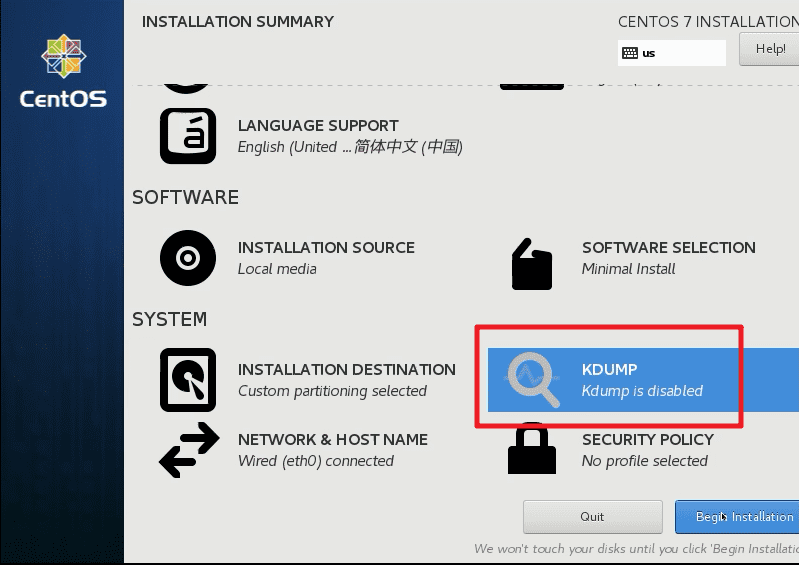
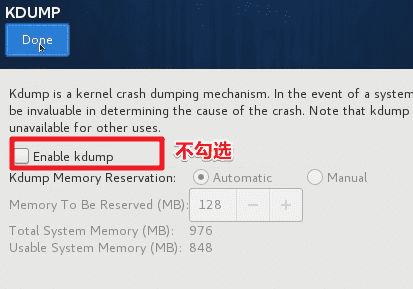
- 禁用KDUMP。
KDUMP 是 Linux 内核的一个功能,可在发生内核错误时创建核心转储。当被触发时,KDUMP 会导出一个内存映像,该映像可用于调试和确定崩溃的原因。
开始安装系统
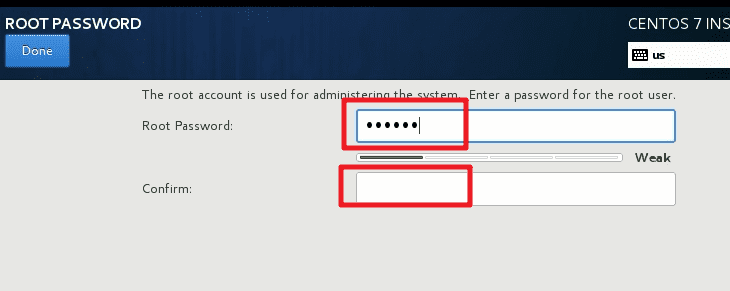
设置 root 密码,密码设置为
123456。此时可能会提示密码过短,但是再次按下Done按钮确认即可成功修改。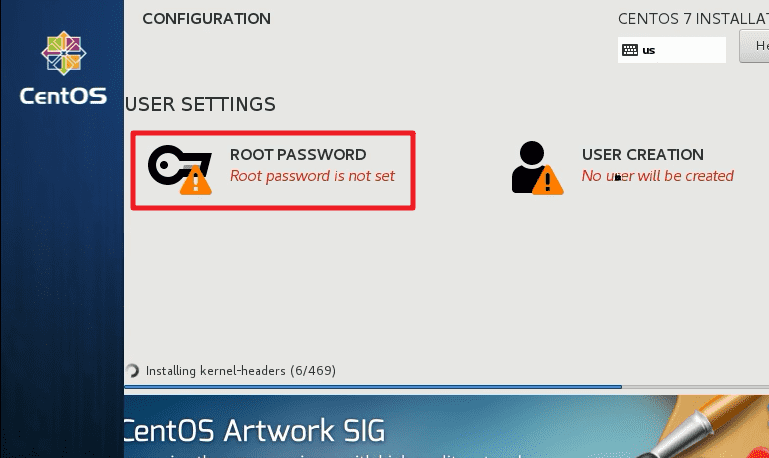
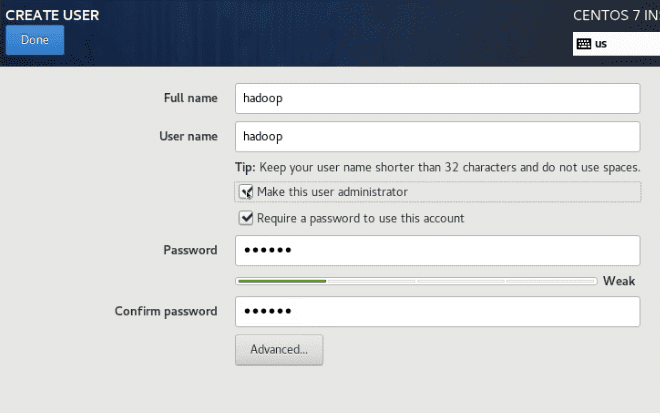
- 创建 hadoop 用户,密码设置为
123456。此时可能会提示密码过短,但是再次按下Done按钮确认即可成功修改。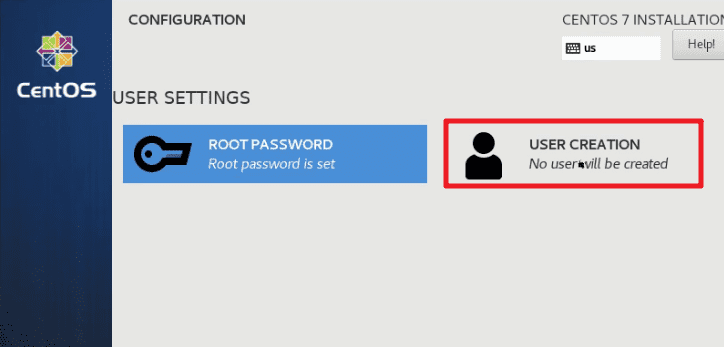
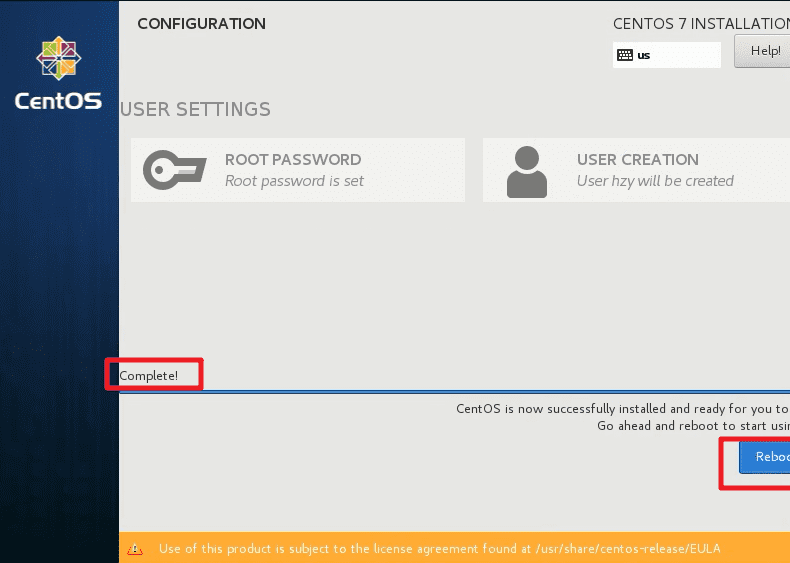
- 等待系统安装完毕以后,点击重启。
配置 CentOS 系统
- 重启以后,尝试使用 hadoop/123456 账户登录。
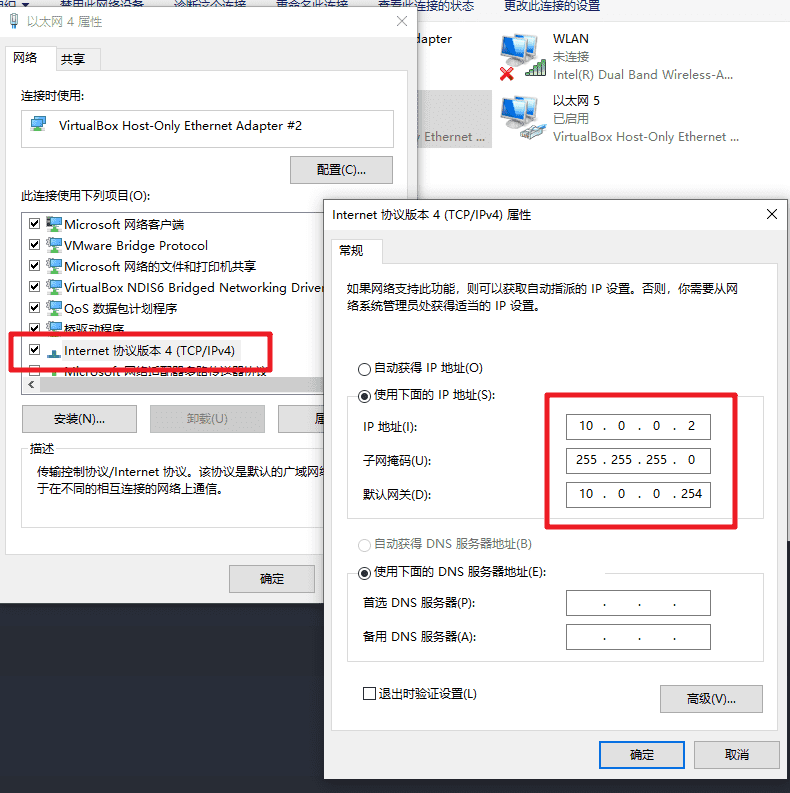
进入当前Windows系统的网卡设置,修改虚拟网卡的配置。
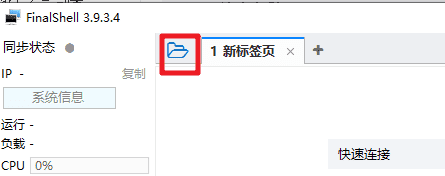
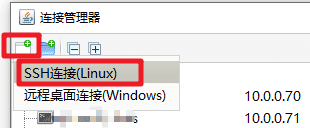
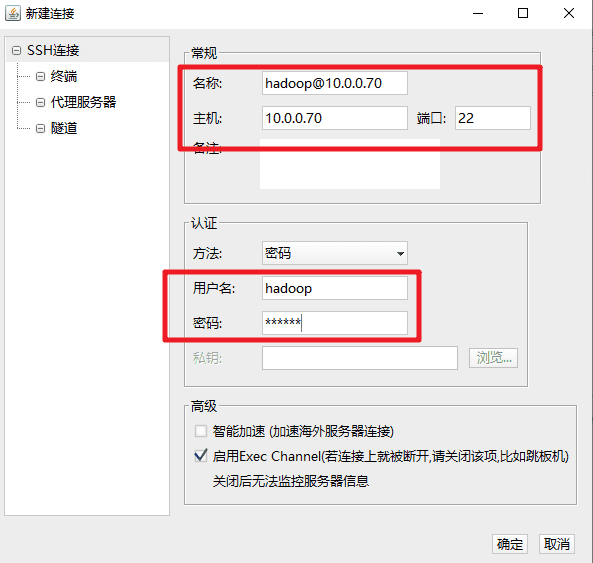
打开FinalShell,使用 hadoop 用户SSH方式登录虚拟机。
IP:10.0.0.70
端口:22
用户名:hadoop
- 使用
su命令,输入root的密码123456,切换为root用户。
su
- 执行以下命令,禁用防火墙。
systemctl stop firewalld
systemctl disable firewalld
- 备份 SELinux 配置文件,并禁用 SELinux。
cp /etc/selinux/config{,.bak}
vi /etc/selinux/config
在文件中修改
SELINUX=disabled
注:此为实验安装,为了尽量方便访问 Hadoop 的服务,所以选择关闭防火墙和SELinux。真实生产部署 Hadoop 不应该禁用防火墙和SELinux,它们对于系统的安全性是至关重要的。
- 关闭图形化networkmanager,以后统一用network来管理
systemctl stop NetworkManager.service
systemctl disable NetworkManager.service
配置 SSH
- 备份 SSH 配置文件,优化 SSH 的连接速度。
cp /etc/ssh/sshd_config{,.bak}
vi /etc/ssh/sshd_config
找到
UseDNS no,去掉前面的#号注释找到
GSSAPIAuthentication no这一行的yes,把yes改成no改完重启sshd
systemctl restart sshd
配置 CentOS yum源
yum,是Yellow dog Updater, Modified 的简称,是杜克大学为了提高RPM 软件包安装性而开发的一种软件包管理器。
起初是由 yellow dog 这一发行版的开发者 Terra Soft 研发,用 Python 写成,那时还叫做yup(yellow dog updater),后经杜克大学的Linux@Duke 开发团队进行改进,遂有此名。
yum 的宗旨是自动化地升级,安装/移除 rpm 包,收集 rpm 包的相关信息,检查rpm包的依赖性并自动提示用户解决。
yum 的关键之处是要有可靠的 repository,顾名思义,这是软件的仓库,它可以是 http 或 ftp 站点,也可以是本地软件池,但必须包含 rpm 的 header,header 包括了rpm 包的各种信息,包括描述,功能,提供的文件,依赖性等。正是收集了这些header 并加以分析,才能自动化地完成余下的任务。
为了提升软件安装速度,我们选择使用本地安装镜像作为 yum 的源。首先确保虚拟机加载了 CentOS 的安装光盘镜像。
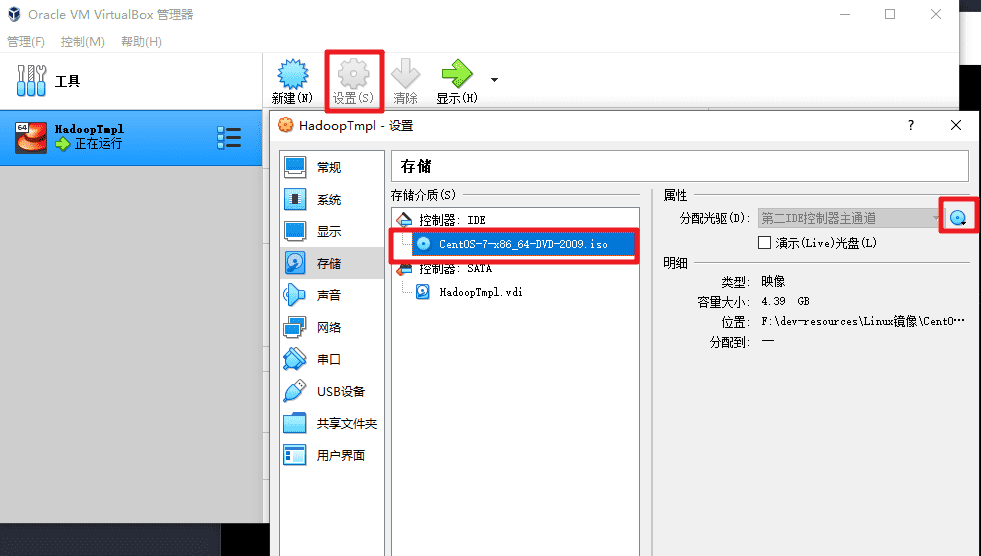
调整硬盘为启动的第一顺位。
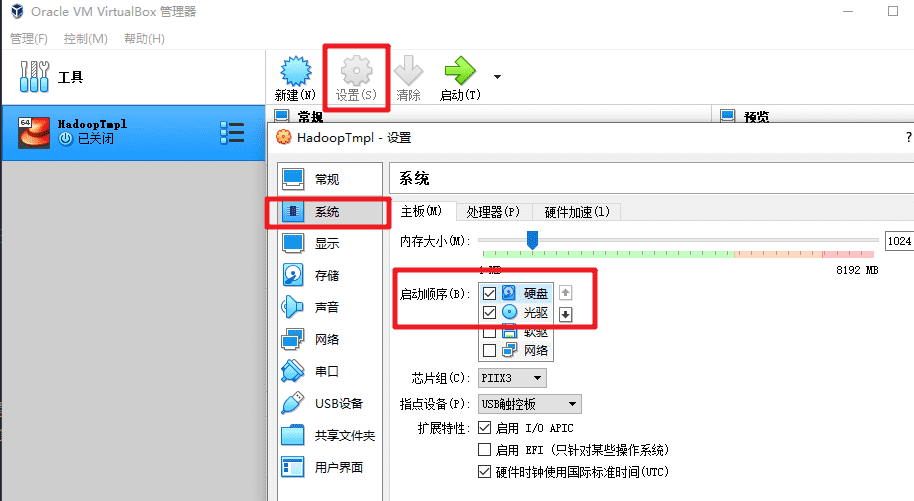
解挂目录 /mnt 目录,准备把光盘挂载到此目录。
umount /mnt
- 进入源目录,把原有源备份到test目录下。
cd /etc/yum.repos.d/
mkdir test -p
mv *.repo test
- 配置本地源指向光盘镜像的挂载目录
/mnt。
echo '[local]
name=local
baseurl=file:///mnt
gpgcheck=0'>local.repo
- 挂载光盘内容到
/mnt目录下
mount /dev/cdrom /mnt
- 清理源缓存
yum makecache
正常清理源缓存以后,会看到以下结果提示:
Determining fastest mirrors
Metadata Cache Created
- 执行以下命令,每次启动系统自动挂载光盘内容到
/mnt目录下。
echo 'mount /dev/cdrom /mnt' >>/etc/rc.local
chmod +x /etc/rc.d/rc.local
CentOS 安装通用软件
- 安装常用的命令
yum install -y net-tools vim lrzsz wget tree screen lsof tcpdump chrony rsync
CentOS 安装 JDK
- 解压安装JDK
cd /opt
tar -xvf jdk-8u291-linux-x64.tar.gz
mv jdk1.8.0_291 jdk8
- 设置 JDK 相关的环境变量,并运行。
cp /etc/profile /etc/profile.bak
echo "export JAVA_HOME=/opt/jdk8
export CLASSPATH=\$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:.
export PATH=\$JAVA_HOME/bin:\$PATH" >>/etc/profile
source /etc/profile
- 测试 JDK 是否正常安装,正常安装的运行以下命令以后可以返回 JDK 的版本。
java -version
- 修改 hosts,在配置文件末尾加入3个节点配置。注意替换为你的学号。
- 备份 hosts 文件,仅执行一次
cp /etc/hosts{,.bak}
- 写入内容到 hosts 文件
echo "10.0.0.71 nodea+你的学号后3位
10.0.0.72 nodeb+你的学号后3位
10.0.0.73 nodec+你的学号后3位">> /etc/hosts
假如你的学号为123,则命令为
echo "10.0.0.71 nodea123
10.0.0.72 nodeb123
10.0.0.73 nodec123">> /etc/hosts
- 打开 hosts 文件查看是否有写入内容
cat /etc/hosts
CentOS 安装 chrony
Chrony是一个开源的软件,像CentOS 7或基于RHEL 7操作系统,已经是默认服务,默认配置文件在 /etc/chrony.conf 它能保持系统时间与时间服务器(NTP)同步,让时间始终保持同步。相对于NTP时间同步软件,占据很大优势。其用法也很简单。
- 安装和设置chrony。打开时间同步配置文件,在文件最后增加以下代码,保存退出。
vim /etc/chrony.conf
server 10.0.0.71 iburst
- 重启时间同步服务
systemctl restart chronyd
CentOS 解压准备 Hadoop
- 切换为 hadoop 用户
su hadoop
- 进入 hadoop 工作目录,上传 Hadoop 安装包
hadoop-3.3.1.tar.gz。
cd ~
- 移动安装包
hadoop-3.3.1.tar.gz到/opt目录并解压。
sudo mv hadoop-3.3.1.tar.gz /opt
sudo tar -xvf hadoop-3.3.1.tar.gz
- 修改 hadoop 存放目录,创建一个 tmp 目录用于存储HDFS文件内容。
cd /opt
sudo mv hadoop-3.3.1 hadoop
sudo mkdir /opt/hadoop/tmp
- 设置 /opt/hadoop 的拥有者为 hadoop 用户·
sudo chown hadoop:wheel -R /opt/hadoop
- 设置 Hadoop 的环境变量。
echo "export HADOOP_HOME=/opt/hadoop
export PATH=\$HADOOP_HOME/bin:\$HADOOP_HOME/sbin:\$PATH:.
">>/etc/profile
- 删除 Hadoop 下cmd后缀的脚本,这些脚本仅能在 Windows 下运行。
sudo rm /opt/hadoop/sbin/*.cmd -f
