【实验手册版本】
当前版本号v20200412
| 版本 | 修改说明 |
|---|---|
| v20200412 | 初始化版本 |
综合练习1
【实验名称】
综合练习1
【实验目的】
综合前四章学习的知识,完成对数据的清洗,提取,维度建模和 OLAP 分析。
【实验数据说明】
- 请从下面链接下载练习数据:
https://pan.baidu.com/s/1Xj6s2evPcx8TpzpHkvjBDA#提取码u0jg
- people.csv 中的数据是中国第五次人口普查(2000年)和第六次人口普查(2010年)的数据。以下为数据列的说明
| 列序号 | 说明 |
|---|---|
| 1 | 地区名称 |
| 2 | 户口地区类型,分别为 城市/镇/乡村 |
| 3 | 户口集体类型,分别为 家庭户/集体户 |
| 4 | 统计年份 |
| 5 | 性别 |
| 6 | 人数 |
其中户口地区类型分为三种,即城市、镇和乡村。每个地区类型下,又按集体类型分为两种,家庭户和集体户。
地区名称列需要进行清洗。
【实验环境】
- 操作系统:Windows
- MySQL
- Saiku
- Python
- Excel
【实验步骤1参考解决方法】
1.使用你学过的编程语言或工具,对people.csv数据进行清洗,并导出清洗后的people.csv。可以使用你熟悉的工具或编程语言。
第一题解决办法参考:实验数据提到地区名称列需要进行清洗。那我们第1步就是需要对数据的地区名称进行查看,思考清洗方法。
方法1:使用 Excel 复制出地区名称列,使用去重和排序进行查看。这种方法只适用于小量的数据(10万条记录以内)。
(1)复制出地区列
(2)使用Excel的删除重复值,并排序查看地区列。

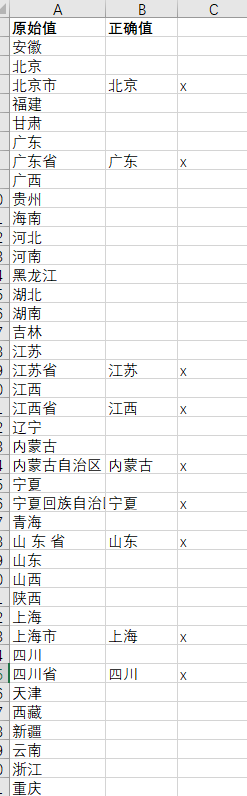
(3)对需要修正的数据进行标注,使用Excel的替换功能(ctrl+H)进行手动替换。
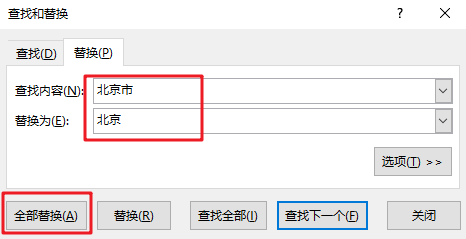
方法2:使用编程方式进行替换。这种方法处理大量的数据会更有效率。以下是Python的清洗代码。
distDict={'上海市':'上海','内蒙古自治区':'内蒙古','北京市':'北京','宁夏回族自治区':'宁夏','山 东 省':'山东','江苏省':'江苏','江西省':'江西','河南省':'河南','湖北省':'湖北','甘肃省':'甘肃','四川省':'四川','广东省':'广东'}
w=open('d:/清洗后-people.csv','w',encoding='utf-8-sig',errors='ignore')
try:
with open('d:/清洗前-people.csv','r',encoding='utf-8-sig') as f:
file =f.read()
lines=file.split('\n')
for line in lines:
cols=line.split(',')
dist=cols[0]
if dist in distDict:
cols[0]=distDict[dist]
rs=','.join(cols)+'\n'
w.write(rs)
finally:
if w:
w.close()
distSet=set([])
with open('d:/清洗后-people.csv','r',encoding='utf-8-sig') as f:
file=f.read()
lines=file.split('\n')
for line in lines:
if line !='':
cols=line.split(',')
distSet.add(cols[0])
dists=list(distSet)
dists.sort()
print(len(dists))
print(dists)
【实验步骤2参考解决方法】
2:把清洗后的 people.csv 导入数据库。可以参考使用以下代码建库,建表和导入。
create database ppstat;
use ppstat;
create user 'ppstat'@'localhost' identified by 'ppstat';
create user 'ppstat'@'%' identified by 'ppstat';
grant all on ppstat.* to 'ppstat'@'localhost';
grant all on ppstat.* to 'ppstat'@'%';
drop table if exists dist_pp;
create table dist_pp(
dist char(20) comment '地区名称',
hk_dtype char(20) comment '户口地区类型,分别为 城市/镇/乡村',
hk_gtype char(20) comment '户口集体类型,分别为 家庭户/集体户',
stat_year char(20) comment '统计年份',
gender char(20) comment '性别',
nop int comment '人数'
)
COMMENT='初始人数统计表'
COLLATE='utf8_general_ci'
ENGINE=InnoDB;
load data infile 'd:/清洗后-people.csv'
into table dist_pp character set utf8
fields terminated by ',' optionally enclosed by '"' escaped by '"'
lines terminated by '\r\n';
【实验步骤3参考解决方法】
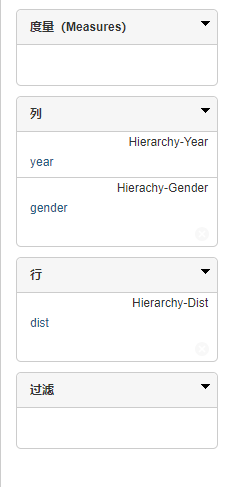
- 接下来的分析会用到
dist_pp表的所有的列,主要分析各个维度下的人数。开始维度建模,先确认dist_pp表中数据哪些是属于维度表,哪些是度量,事实表应该如何构造。画出星型模型。
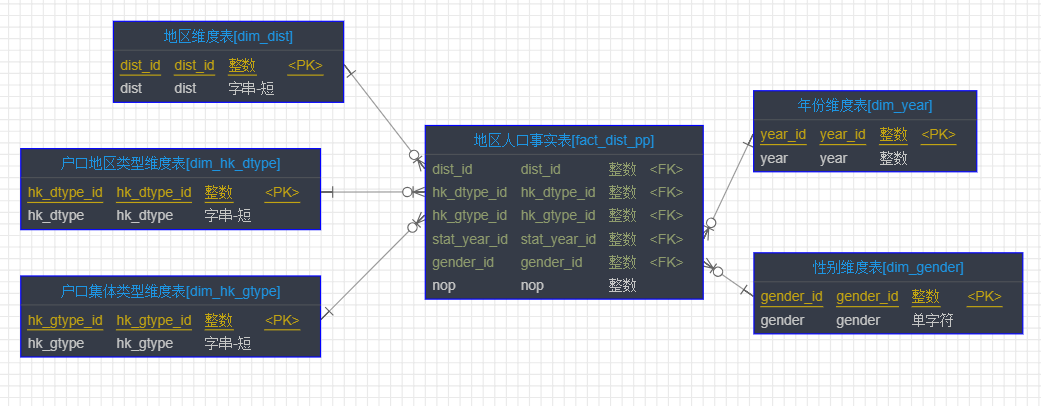
【实验步骤4参考解决方法】
- 根据星型模式,编写 SQL 脚本。例如构造性别维度表脚本如下。
/* 构建性别维度表 */
drop table if exists dim_gender;
CREATE TABLE dim_gender(
gender_id INT NOT NULL COMMENT 'gender_id 性别ID' ,
gender CHAR(1) COMMENT 'gender 性别' ,
PRIMARY KEY (gender_id)
)
COLLATE='utf8_general_ci'
COMMENT = '性别维度表'
ENGINE=InnoDB;
insert into dim_gender (gender_id,gender) values(1,'男');
insert into dim_gender (gender_id,gender) values(2,'女');
/* 构建地区维度表 */
drop table if exists dim_dist;
CREATE TABLE dim_dist(
dist_id INT NOT NULL COMMENT 'dist_id 地区ID' ,
dist VARCHAR(128) COMMENT 'dist 地区' ,
PRIMARY KEY (dist_id)
)
COLLATE='utf8_general_ci'
COMMENT = '地区维度表'
ENGINE=InnoDB;
set @row=0;
insert into dim_dist select (@row:=@row+1) as dist_id,dist from (select dist from dist_pp group by dist) a;
/* 构建户口地区类型维度表 */
drop table if exists dim_hk_dtype;
CREATE TABLE dim_hk_dtype(
hk_dtype_id INT NOT NULL COMMENT 'hk_dtype_id 户口地区类型ID' ,
hk_dtype VARCHAR(128) COMMENT 'hk_dtype 户口地区类型' ,
PRIMARY KEY (hk_dtype_id)
)
COLLATE='utf8_general_ci'
COMMENT = '户口地区类型维度表'
ENGINE=InnoDB;
set @row=0;
insert into dim_hk_dtype select (@row:=@row+1) as hk_dtype_id,hk_dtype from (select hk_dtype from dist_pp group by hk_dtype) a;
/* 构建户口集体类型维度表 */
drop table if exists dim_hk_gtype;
CREATE TABLE dim_hk_gtype(
hk_gtype_id INT NOT NULL COMMENT 'hk_gtype_id 户口地区类型ID' ,
hk_gtype VARCHAR(128) COMMENT 'hk_gtype 户口地区类型' ,
PRIMARY KEY (hk_gtype_id)
)
COLLATE='utf8_general_ci'
COMMENT = '户口集体类型维度表'
ENGINE=InnoDB;
set @row=0;
insert into dim_hk_gtype select (@row:=@row+1) as hk_gtype_id,hk_gtype from (select hk_gtype from dist_pp group by hk_gtype) a;
/* 构建年份维度表 */
drop table if exists dim_year;
CREATE TABLE dim_year(
year_id INT NOT NULL COMMENT 'year_id 年份ID' ,
year INT COMMENT 'year 年份' ,
PRIMARY KEY (year_id)
)
COLLATE='utf8_general_ci'
COMMENT = '年份维度表'
ENGINE=InnoDB;
set @row=4;
insert into dim_year select (@row:=@row+1) as year_id,stat_year from (select stat_year from dist_pp group by stat_year) a;
/* 事实表*/
drop table if exists fact_dist_pp;
CREATE TABLE fact_dist_pp(
dist_id INT COMMENT 'dist_id 地区ID' ,
hk_dtype_id INT COMMENT 'hk_dtype_id 户口地区类型ID' ,
hk_gtype_id INT COMMENT 'hk_gtype_id 户口集体类型ID' ,
stat_year_id INT COMMENT 'stat_year_id 统计年ID' ,
gender_id INT COMMENT 'gender_id 性别ID' ,
nop INT COMMENT 'nop 人数'
)
COLLATE='utf8_general_ci'
COMMENT = '地区人口事实表'
ENGINE=InnoDB;
通过原始表连接各个维度表来构建事实表。
insert into fact_dist_pp
select dist_id,hk_dtype_id,hk_gtype_id,stat_year_id,gender_id,nop
from (
select b.dist_id,d.hk_dtype_id,e.hk_gtype_id,f.year_id as stat_year_id,c.gender_id,a.nop
from dist_pp a
left join dim_dist b on a.dist=b.dist
left join dim_gender c on a.gender=c.gender
left join dim_hk_dtype d on a.hk_dtype=d.hk_dtype
left join dim_hk_gtype e on a.hk_gtype=e.hk_gtype
left join dim_year f on a.stat_year=f.year
) fact
【实验步骤5参考解决方法】
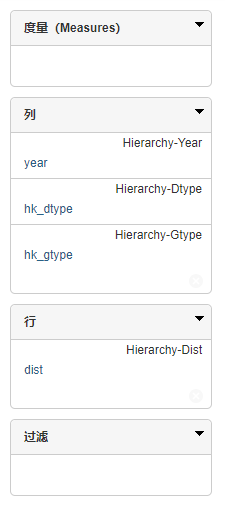
- 根据ppstat数据库来构造多维的数据集Cube。使用Schema Workbench来进行构造。
<Schema name="New Schema1">
<Cube name="Cube-ppstat" visible="true" description="人口普查数据分析" cache="true" enabled="true">
<Table name="fact_dist_pp">
</Table>
<Dimension type="StandardDimension" visible="true" foreignKey="dist_id" highCardinality="false" name="dim_dist">
<Hierarchy name="Hierarchy-Dist" visible="true" hasAll="true" primaryKey="dist_id" primaryKeyTable="dim_dist">
<Table name="dim_dist">
</Table>
<Level name="dist" visible="true" table="dim_dist" column="dist" type="String" uniqueMembers="false" levelType="Regular" hideMemberIf="Never">
</Level>
</Hierarchy>
</Dimension>
<Dimension type="StandardDimension" visible="true" foreignKey="gender_id" name="dim_gender">
<Hierarchy name="Hierachy-Gender" visible="true" hasAll="true" primaryKey="gender_id" primaryKeyTable="dim_gender">
<Table name="dim_gender">
</Table>
<Level name="gender" visible="true" table="dim_gender" column="gender" type="String" uniqueMembers="false">
</Level>
</Hierarchy>
</Dimension>
<Dimension type="StandardDimension" visible="true" foreignKey="hk_dtype_id" name="dim_hk_dtype">
<Hierarchy name="Hierarchy-Dtype" visible="true" hasAll="true" primaryKey="hk_dtype_id" primaryKeyTable="dim_hk_dtype">
<Table name="dim_hk_dtype">
</Table>
<Level name="hk_dtype" visible="true" table="dim_hk_dtype" column="hk_dtype" type="String" uniqueMembers="false">
</Level>
</Hierarchy>
</Dimension>
<Dimension type="StandardDimension" visible="true" foreignKey="hk_gtype_id" name="dim_hk_gtype">
<Hierarchy name="Hierarchy-Gtype" visible="true" hasAll="true">
<Table name="dim_hk_gtype">
</Table>
<Level name="hk_gtype" visible="true" table="dim_hk_gtype" column="hk_gtype" type="String" uniqueMembers="false">
</Level>
</Hierarchy>
</Dimension>
<Dimension type="StandardDimension" visible="true" foreignKey="stat_year_id" name="dim_year">
<Hierarchy name="Hierarchy-Year" visible="true" hasAll="true">
<Table name="dim_year">
</Table>
<Level name="year" visible="true" table="dim_year" column="year" type="Integer" uniqueMembers="false">
</Level>
</Hierarchy>
</Dimension>
<Measure name="nop" column="nop" aggregator="sum" visible="true">
</Measure>
</Cube>
</Schema>
【实验步骤6参考解决方法】
- 根据上一步生成的多维数据集Cube,导入Saiku,并增加数据源。按以下表头查询数据。