【实验手册版本】
当前版本号v20200605
| 版本 | 修改说明 |
|---|---|
| v20200605 | 实验6.1新增了校验测试结果的步骤 |
| v20200527 | 修正了数据库连接的问题,修正航空里程列SEG_KM_COUNT为SEG_KM_SUM |
| v20200513 | 初始化版本 |
实验6.1:超市客户信息分类预测
【实验名称】
实验6.1:超市客户信息分类预测
【实验目的】
根据现有超市客户数据构造客户分类模型
使用分类模型对客户数据进行预测
熟悉并学会使用weka智能分析环境;
【实验内容】
使用 Weka 的分类模型对现有 foodmart 数据库客户信息进行建模,获取到建模以后,使用模型对数据进行预测。
【实验环境】
- Windows 操作系统。
- JDK
- MySQL
- Foodmart 数据集
- Weka:Weka 的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),是一款免费的,非商业化(与之对应的是SPSS公司商业数据挖掘产品–Clementine )的,基于JAVA环境下开源的机器学习(machine learning)以及数据挖掘(data mining)软件。Weka 作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。
【实验资源】
实验报告模板下载
https://pan.baidu.com/s/1qqhcPcQotylS3PNP4f-edg#提取码vidt
实验数据下载
https://pan.baidu.com/s/12iBkrHWzt20QJg7OlwPkrQ#提取码e6rx
Weka 网盘下载:
https://pan.baidu.com/s/1dQEeVmqbyt11mZV7Uge_kQ#提取码2oev
如果网盘下载速度过慢,可以尝试从 Weka 官网下载:
https://sourceforge.net/projects/weka/files/weka-3-9/3.9.4/weka-3-9-4-azul-zulu-windows.exe/download
【实验步骤】
1.获取实验资源提供的 weka.jar,替换掉 Weka 安装目录下的 weka.jar。
原有的 weka.jar 对于MySQL数据库的链接有兼容性问题。因此修改了包内的 weka/experiment/DatabaseUtils.props 来解决这个问题。
- 修改 Weka 安装目录下的
RunWeka.ini,修改cp=这行,在%CLASSPATH% 后面加入 MySQL JDBC 驱动包的路径。这一步是为了Weka 启动以后引用到 MySQL 驱动包,否则无法连接 MySQL。
注意:
- 驱动包的路径与%CLASSPATH% 之间使用英文分号隔开
- 路径的
\需要替换为/ - 存放驱动包的路径不能出现空格或者中文字符
#修改为你的驱动包所在路径
cp=%CLASSPATH%;F:/mysql-connector-java-5.1.48-bin.jar
运行 Weka,启动
Explorer.
点击
OpenDB,设置数据库连接。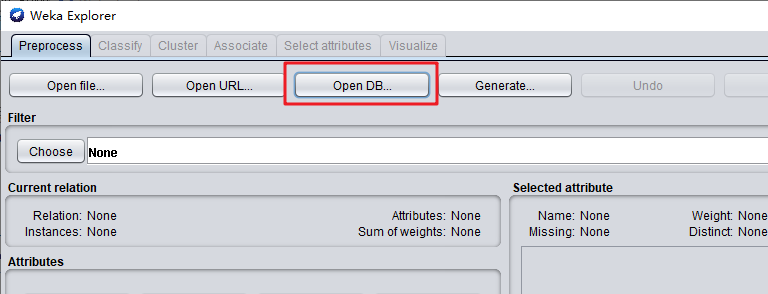
这次使用到的是foodmart数据库,是我们第三章实验创建的。配置数据库的连接,用户名和密码。
URL 连接:jdbc:mysql://localhost:3306/foodmart?characterEncoding=UTF-8&charactSetResults=UTF-8&zeroDateTimeBehavior=convertToNull
用户名:foodmart
密码:foodmart
- 连接数据库,并输入以下 SQL 查询客户信息。

select * from customer;
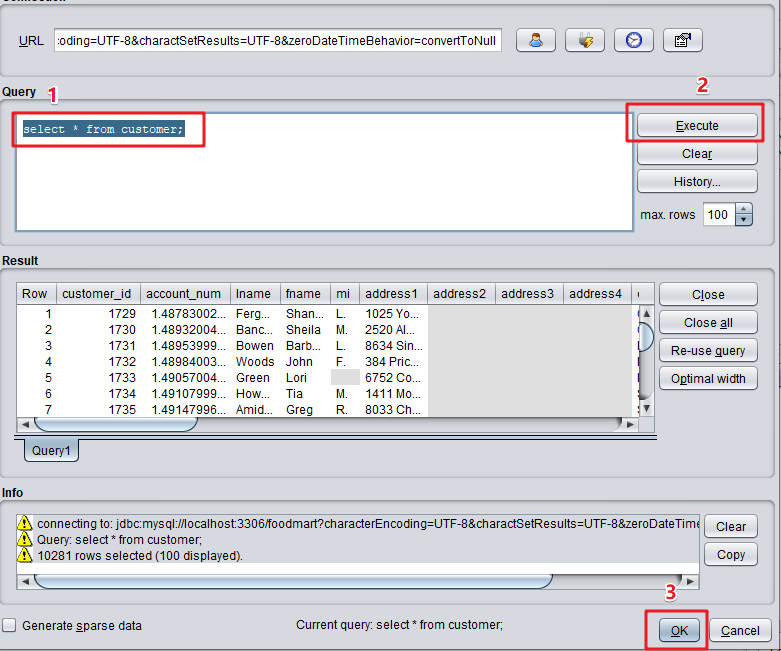
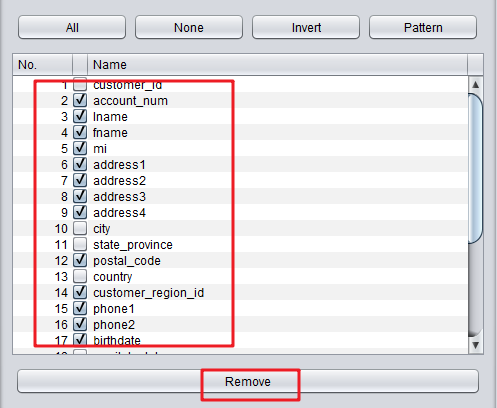
- 在列出的列中,我们并不需要全部的列,可以勾选其中的列进行删除。注意以下的列式需要保留的。
#请保留以下列
customer_id
city
state_province
country
marital_status
yearly_income
gender
total_children
num_children_at_home
education
member_card
occupation
houseowner
num_cars_owned
- 我们需要对数据进行预处理转换。这里把 numberic 类型转换为 nominal 类型。
numberic 类型:数字类型,可以排序,但是无法分类。 nominal 类型:可以分类,但不能排序的变量,比如血型,性别,职业等。
Choose 弹窗中选择 NumericToNominal
weka
|- filters
|- unsupervised
|- attribute
|- NumericToNominal

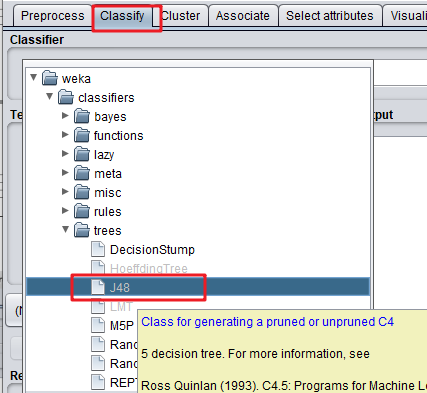
- 接下来进行建模(Build Model)操作,选择的聚类的方式,选择上方的 Classify 选项卡,在此界面中点击 choose,选择相应的算法,这里我选择的是 j48 决策树,Test options 中选择的第一项,需要分类的列选择的 member_card。
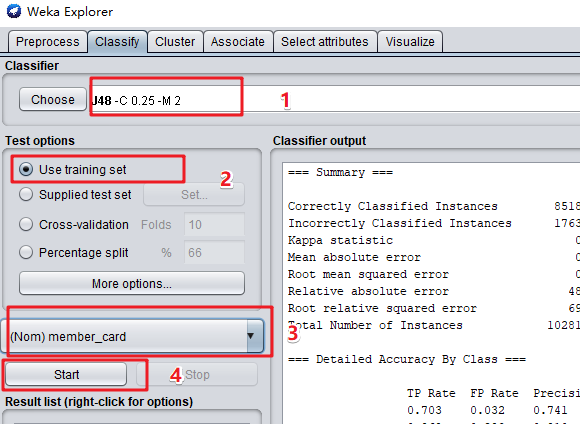
- 在右侧输出的数据中,我们可以观察到分类结果数据。
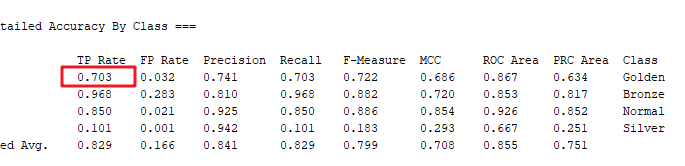
(1)其中我们可以观察到分类的正确率为82.8519%。

(2)从下面的混淆矩阵(Confusion Matrix)中可以查看分类的结果。例如第一行中,a/b/c/d分别表示Golden(金牌会员)/铜牌会员(Bronze)/普通会员(Normal)/银牌会员(Silver);
混淆矩阵第1行表示:实际金牌会员中,有842条分类结果正确;311条别错误识别为铜牌会员(b=Bronze);43条被识别为普通会员(c=Normal);2条被错误识别为银牌会员(d=Silver)。
因此金牌会员的TP计算公式
TP=分类正确金牌会员数量/实际金牌会员数量=842/(842+311+43+2)=0.703

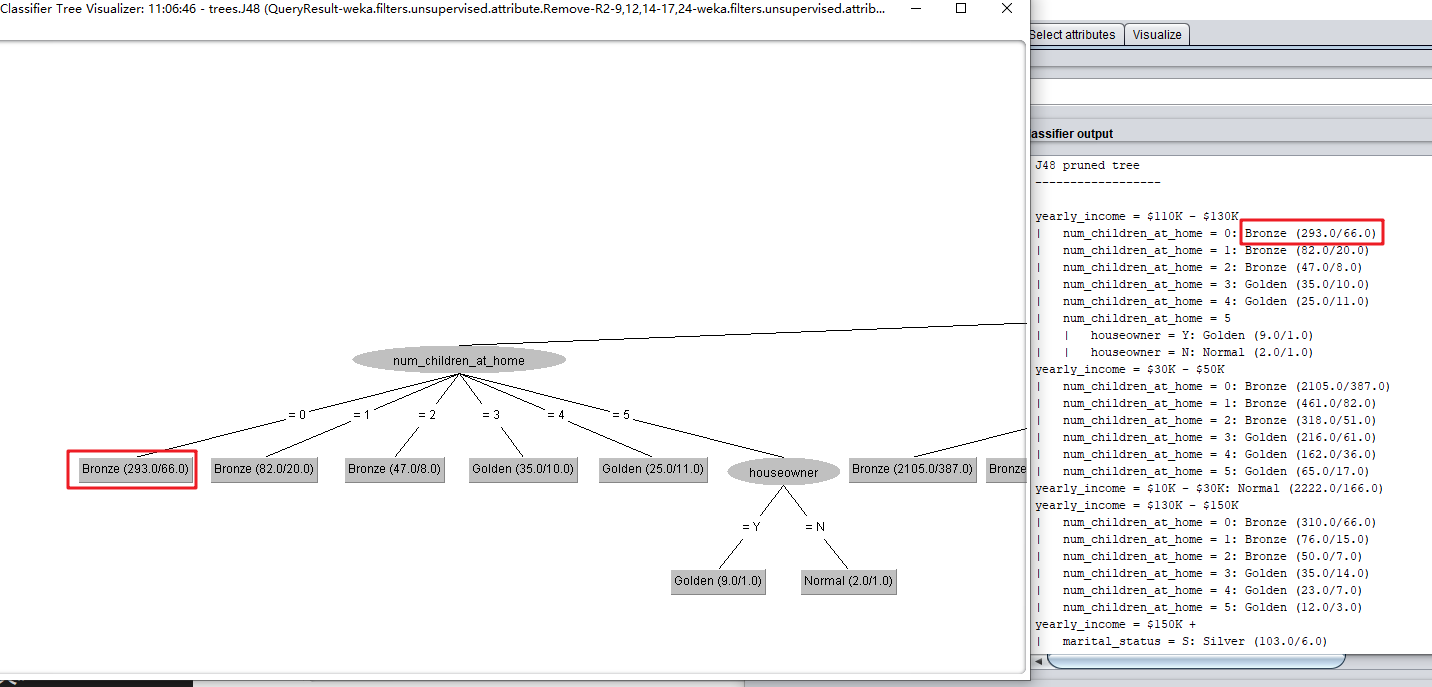
(3)观察 J48 pruned tree,可以看到树状的分类结构分为了以下几级。
家庭年收入(yearly_income)
|- 家庭孩子数量(num_children_at_home)
|- 拥有房产(houseowner)
以年收入110K - 130K为例,家庭孩子数量(num_children_at_home)是0的客户中,总共有293人,其中227人(293-66)是铜牌会员(Bronze)。则模型会使用年收入,家庭孩子数量这2个特征作为预测。
yearly_income = $110K - $130K
| num_children_at_home = 0: Bronze (293.0/66.0)
| num_children_at_home = 1: Bronze (82.0/20.0)
| num_children_at_home = 2: Bronze (47.0/8.0)
| num_children_at_home = 3: Golden (35.0/10.0)
| num_children_at_home = 4: Golden (25.0/11.0)
| num_children_at_home = 5
| | houseowner = Y: Golden (9.0/1.0)
| | houseowner = N: Normal (2.0/1.0)
同学们可以使用以下SQL 查询数据库 foodmart 进行验证。
SELECT member_card,COUNT(*) as n FROM customer WHERE yearly_income='$110K - $130K' AND num_children_at_home=0 group by member_card
union
select 'total',count(*) as n FROM customer WHERE yearly_income='$110K - $130K' AND num_children_at_home=0;
- 对分类树进行可视化。
(1)右键点击结果集,选择“Visualize tree”,查看可视化树状图。
(2)右键点击树状图,点击“Auto Scale” 展开查看。
(3)这里展开的树状图实际上就是“J48分类的剪枝树”(J48 pruned tree)。
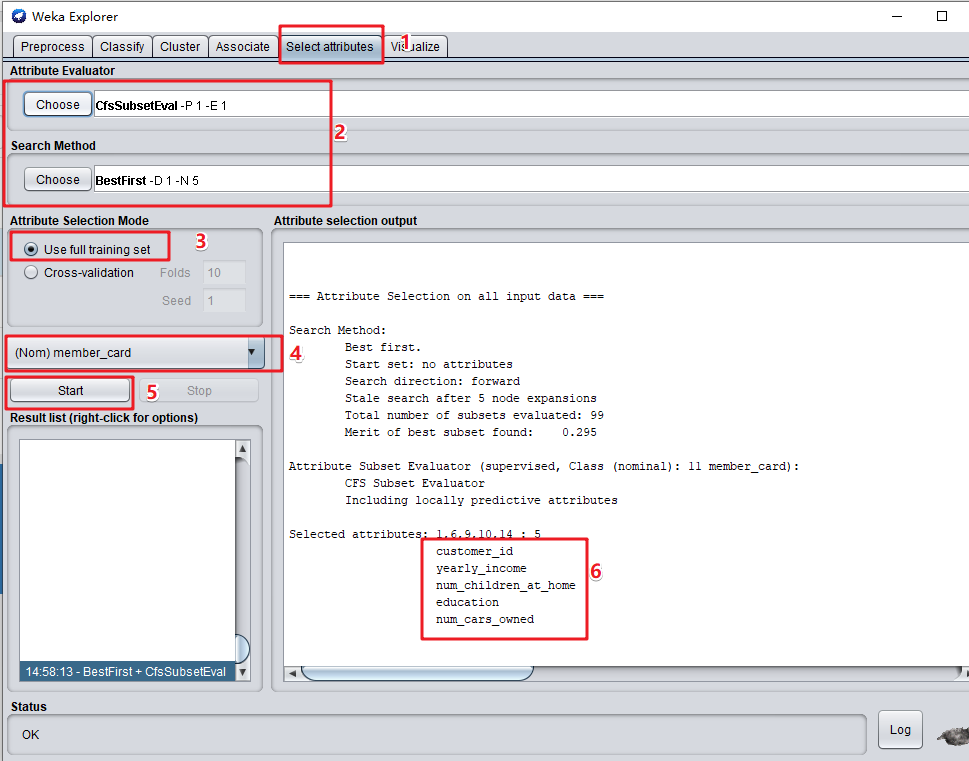
查看分类特征的重要程度。点击“Select attributes”,按下图步骤操作,查看分类特征重要程度排列。
应用模型到测试数据,查看预测结果。
(1)勾选“Supplied test set”,点击“Set…”
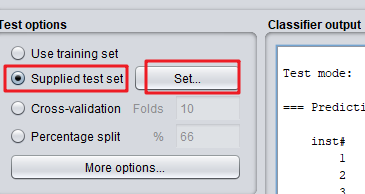
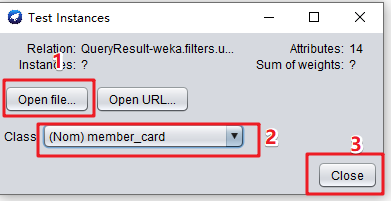
(2)“Open file”选中测试数据集foodmart2008_predict_data.arff;Class选择 “member_card”,然后点击close关闭。
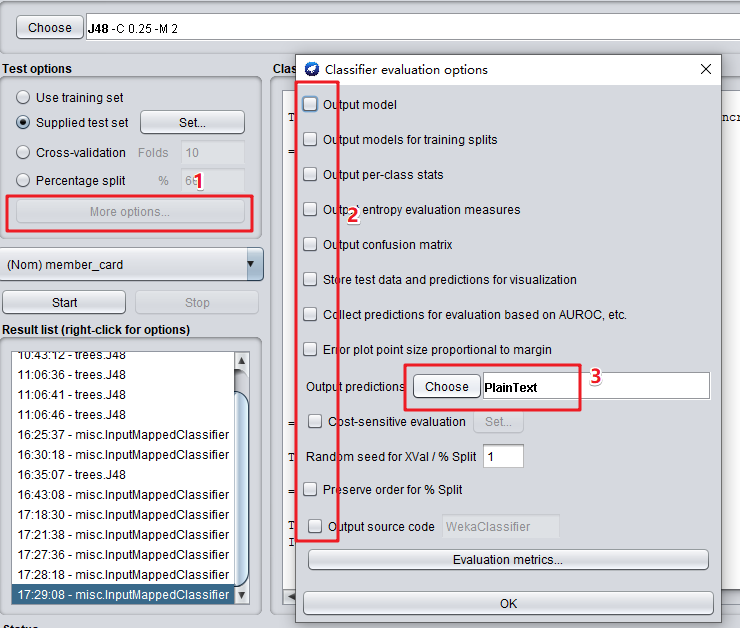
(3)点击“More options”,去掉全部的选项的勾选,输出预测格式(Output predictions)这里选择PlainText。
(4)点击“Start”,弹窗会提示数据转换,点击“是”。
(5)请观测输出的预测结果,并与原训练数据进行对比(参考以下SQL查询出来的数据),计算出四种会员的混淆矩阵。
预测值
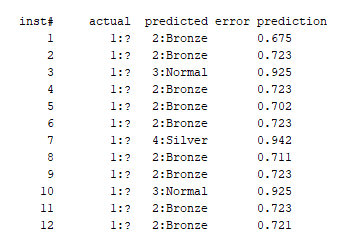
训练数据真实值
SELECT customer_id,city,state_province,country,marital_status,yearly_income,gender,total_children,num_children_at_home,education,member_card,occupation,houseowner,num_cars_owned FROM customer where customer_id >=1729 and customer_id <=1740
完成下面的混淆矩阵表
| 真实值\预测值 | Golden | Silver | Bronze | Normal |
|---|---|---|---|---|
| Golden | ||||
| Silver | ||||
| Bronze | ||||
| Normal |
- 测试结果核对。
(1)获取实验资源中的foodmart2008_predict_data_label.arff数据。
(2)勾选“Supplied test set”,点击“Set…”
(3)“Open file”选中测试数据集foodmart2008_predict_data_label.arff;Class选择 “member_card”,然后点击close关闭。
(4)点击“More options”,勾选Output confusion matrix,输出预测格式(Output predictions)选择PlainText。
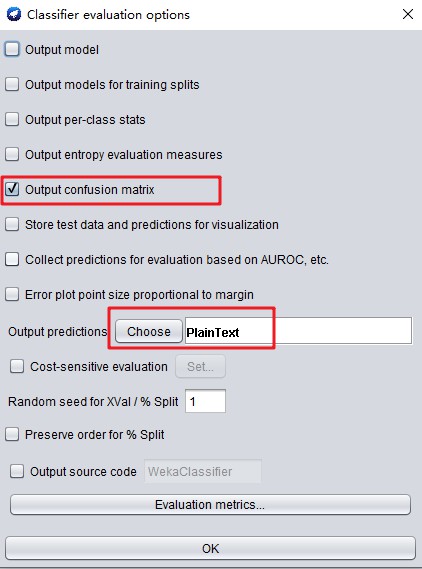
(5)点击“Start”,弹窗会提示数据转换,点击“是”。
(6)观察以下2个部分的数据,核对你的混淆矩阵是否正确。
=== Predictions on test set ===
=== Confusion Matrix ===
实验6.2:航空客运信息挖掘
【实验名称】
实验6.2:航空客运信息挖掘
【实验目的】
熟悉并学会使用weka智能分析环境;
根据数据源建立数据模型;
根据业务逻辑,按照 LRFMC 模型进行数据变换;
使用数据来进行分类预测客户的流失率;
【实验内容】
本实验的目标是客户价值识别,即对客户进行分类。识别客户价值最广泛的模型是通过RFM指标来对客户进行细分,识别出高价值的客户:
-Recency 最近消费时间间隔
-Frequency 消费频率
-Monetary 消费金额
在RFM模型中,消费金额表示在一段时间内,客户购买该企业产品金额的总和。但在本实验中,基于航空机票价格的多变性,同样消费金额的不同旅客对航空公司的价值是不同的。例如,一位购买长航线、低等级舱位票的旅客与一位购买短航线、高等级舱位票的旅客相比,自然是后者对于航空公司而言价值更高。
因此,在本实验中,我们将消费金额指标使用“客户在一定时间内累积的飞行里程M”和“客户在一定时间内乘坐舱位所对应的折扣系数的平均值C”来代替。由于航空公司会员入会时间的长短在一定程度上能够影响客户价值,我们在模型中增加客户关系长度L这一个指标。
本实验将客户关系长度L、消费时间间隔R、消费频率F、飞行里程M和折扣系数的平均值C五个指标作为航空公司识别客户价值指标,记为LRFMC模型。
【数据准备】
(1)数据清理:数据中存在缺失值、折扣率为0、票价为零而总飞行公里数大于0的情况,使用Kettle对其进行清理
(2)数据转换:计算LRFMC,并将结果保存为CSV文件
L(入会时长) = LOAD_TIME - FFP_DATE (观测窗口的结束时间 - 入会时间 )
R(最近一次乘坐的时长) = DAYS_FROM_LAST_TO_END
F(乘坐频率) = FLIGHT_COUNT
M(累积里程) = SEG_KM_SUM
C(平均折扣率) = AVG_DISCOUNT
【实验环境】
- Windows 操作系统。
- JDK
- Weka:Weka 的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),是一款免费的,非商业化(与之对应的是SPSS公司商业数据挖掘产品–Clementine )的,基于JAVA环境下开源的机器学习(machine learning)以及数据挖掘(data mining)软件。Weka 作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。
【实验资源】
实验报告模板下载
https://pan.baidu.com/s/1qqhcPcQotylS3PNP4f-edg#提取码vidt
实验数据下载
https://pan.baidu.com/s/12iBkrHWzt20QJg7OlwPkrQ#提取码e6rx
Weka 网盘下载:
https://pan.baidu.com/s/1dQEeVmqbyt11mZV7Uge_kQ#提取码2oev
如果网盘下载速度过慢,可以尝试从 Weka 官网下载:
https://sourceforge.net/projects/weka/files/weka-3-9/3.9.4/weka-3-9-4-azul-zulu-windows.exe/download
【实验步骤】
一、 因为我们的目标数据是获取票价不为空,而且折扣率大于0,而且用户不是单纯使用积分兑换里程,因此我们要使用 Kettle 对 Excel 数据进行清洗。我们获取目标数据列分别是
- L(入会时长) = LOAD_TIME - FFP_DATE (观测窗口的结束时间 - 入会时间 )
- R(最近一次乘坐的时长) = DAYS_FROM_LAST_TO_END
- F(乘坐频率) = FLIGHT_COUNT
- M(累积里程) = SEG_KM_SUM
- C(平均折扣率) = AVG_DISCOUNT
- 打开Kettle,建立如下图的清洗步骤。
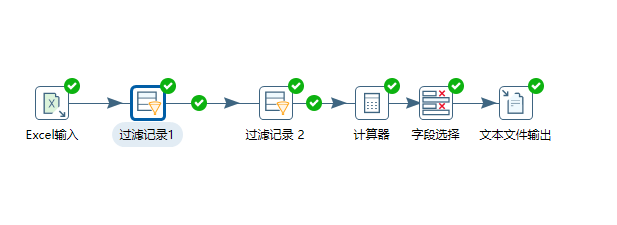
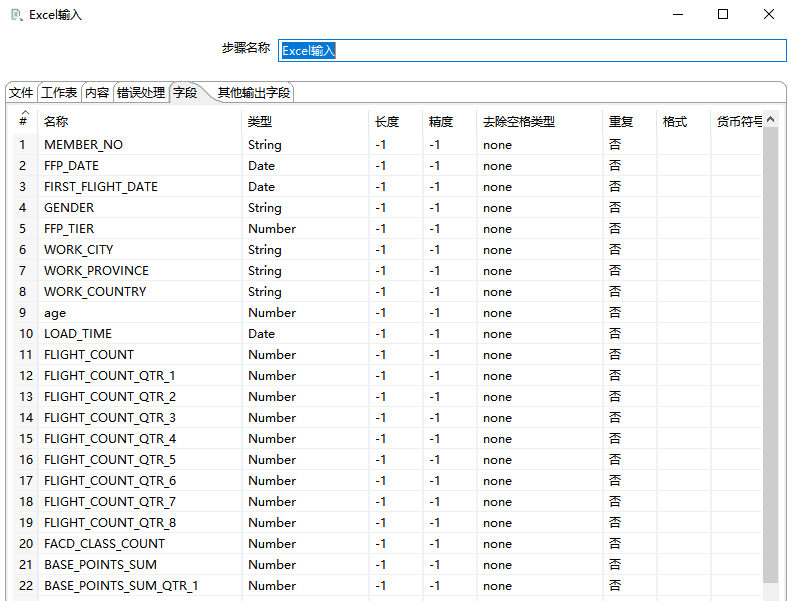
- (1)Excel 输入(Microsoft Excel Input):
文件:航空客运信息挖掘.xls
工作表(Sheet):航空公司客户数据
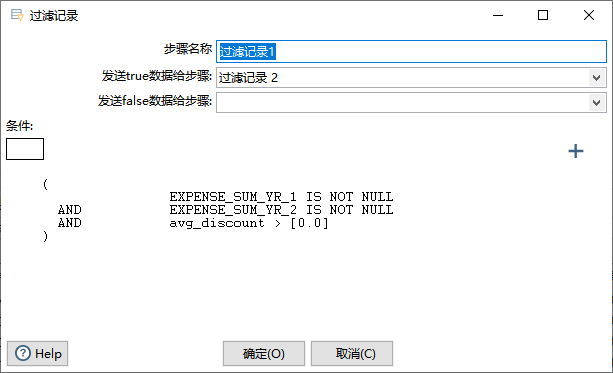
- (2)过滤记录1(Filter Rows):过滤出总票价不为空,而且折扣率大于0的数据。
#第一年总票价不为空 而且 第二年总票价不为空 而且 平均折扣率大于0
EXPENSE_SUM_YR_1 IS NOT NULL
AND
EXPENSE_SUM_YR_2 IS NOT NULL
AND
AVG_DISCOUNT > 0
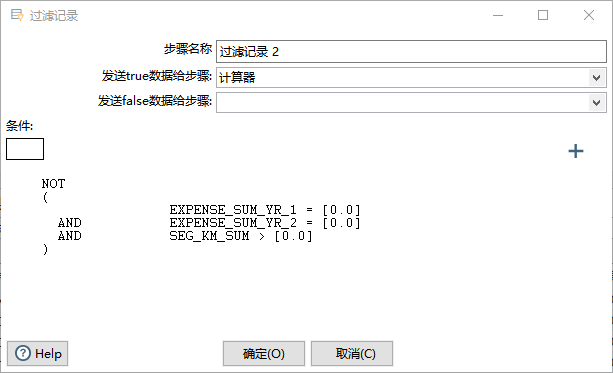
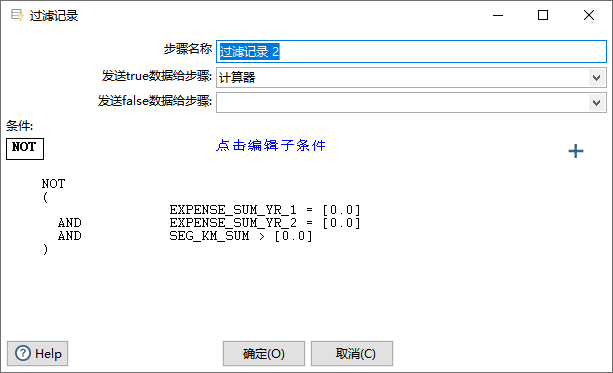
- (3)过滤记录2(Filter Rows):过滤出不单纯使用积分兑换里程的用户。
# 两年总票价都是0,但是里程数不为0的用户要清洗掉。
NOT
(EXPENSE_SUM_YR_1 = 0
AND
EXPENSE_SUM_YR_2 = 0
AND
SEG_KM_SUM>0)
- (4)计算器(Calculator):计算入会时间并赋值给新的列 L,使用“观测窗口的结束时间”(LOAD_TIME)减去“入会时间”(FFP_DATE)
新字段(New field):L
计算(Calculate):Date A - Date B (in days)
字段A(Field A):LOAD_TIME
字段B(Field B):FFP_DATE
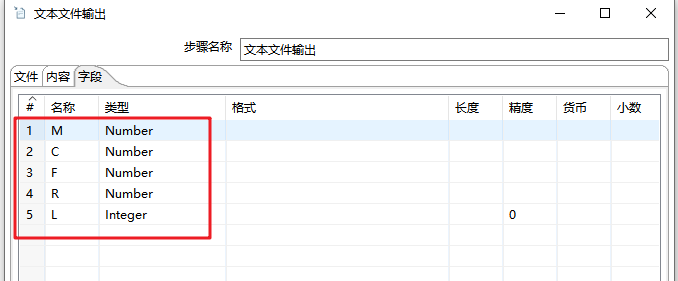
- (5)字段选择(Select Values):选择要输出的字段,并重命名
#字段名->重命名为
L -> L
DAYS_FROM_LAST_TO_END -> R
FLIGHT_COUNT -> F
SEG_KM_SUM -> M
AVG_DISCOUNT -> C
- (6)文本文件输出(Text File Output):输出为CSV文件
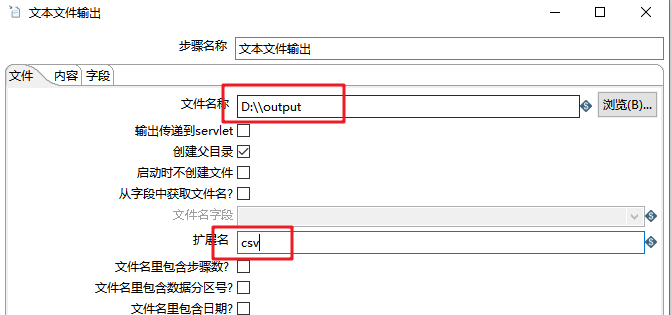
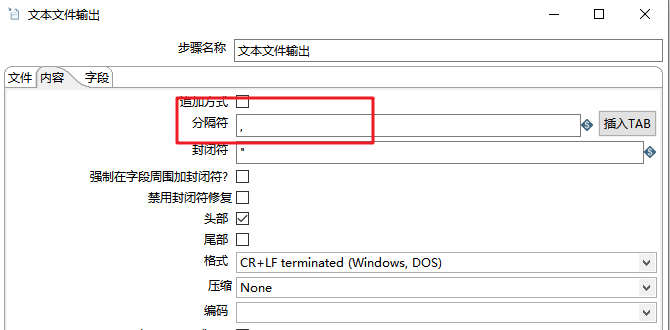
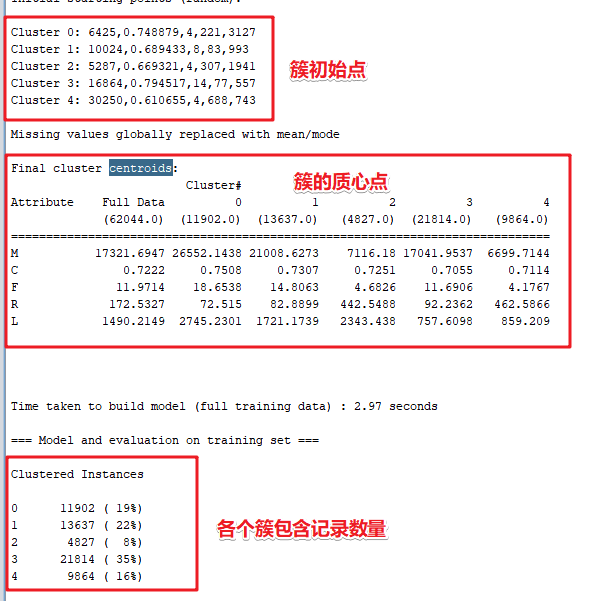
- 执行Kettle程序,查看输出,此时output.csv 内有62044条数据。
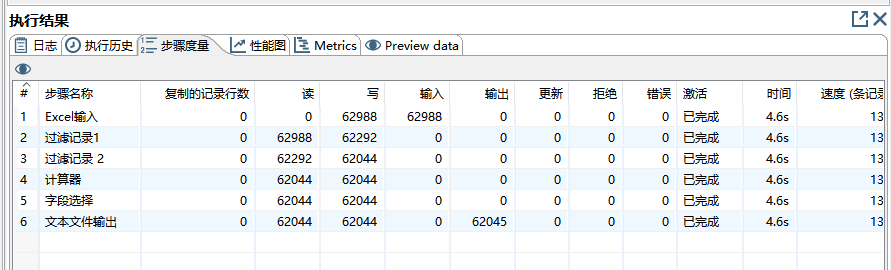
二、使用 Weka 对数据做聚类分析。
打开 Weka 的 Explorer
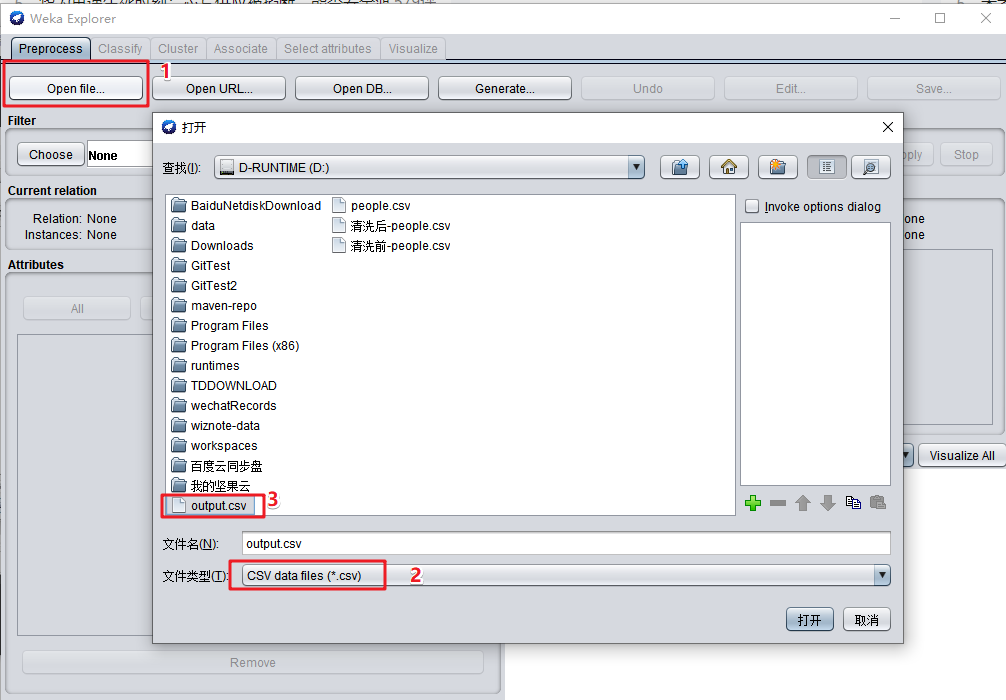
打开 output.csv,导入数据。
- 打开“Cluster”选项卡,Choose按钮选择“Simple KMeans”算法,做聚类分析。
- 点击“SimpleKMeans”,簇的数量(numClusters)选择5。
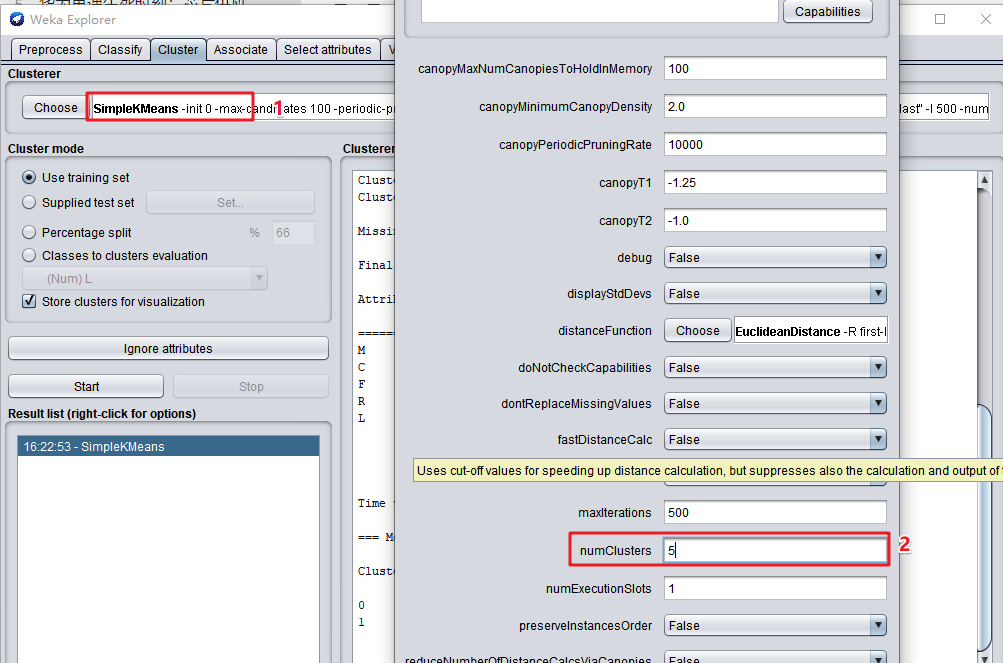
- 点击“Start”按钮,计算并查看结果。
- 右键点击运行结果,选择“Visualized Cluster Assignment”
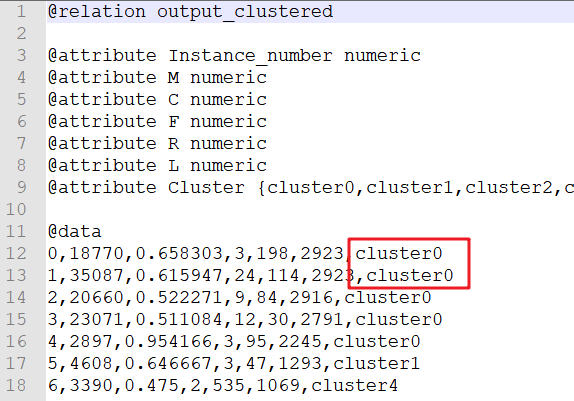
- 保存聚类结果为
airline-cust-clusters.arff文件。
- 打开
airline-cust-clusters.arff文件,查看聚类结果。