商务智能方法与应用第五章实验手册
文章导航
【实验手册版本】
当前版本号v20200824
| 版本 | 修改说明 |
|---|---|
| v20200824 | 修正敏感词 |
| v20200331 | 修正分析结果 |
| v20200327 | 初始化版本 |
实验5.1:购物篮关联性推荐
【实验名称】
实验5.1:购物篮关联性推荐
【实验目的】
熟悉并学会使用weka智能分析环境;
根据数据源建立数据模型;
根据数据模型对购物篮数据进行关联性分析;
【实验内容】
本实验利用weka智能分析软件,对购物篮销售数据进行关联性分析,从而得出商店如何摆放产品将有利于提高我们的销售额度。
【实验相关知识解读】
Apriori 算法是一种最有影响力的挖掘布尔关联规则的频繁项集的 算法,它是由Rakesh Agrawal 和RamakrishnanSkrikant 提出的。了解更多信息可以参考这篇文章
机器学习领域经典的 FP-growth(Frequent Pattern Growth)模型,它是目前业界经典的频繁项集和关联规则挖掘的算法。相比于 Apriori 模型,FP-growth 模型只需要扫描数据库两次,极大得减少了数据读取次数并显著得提升了算法效率。了解更多信息可以参考这篇文章
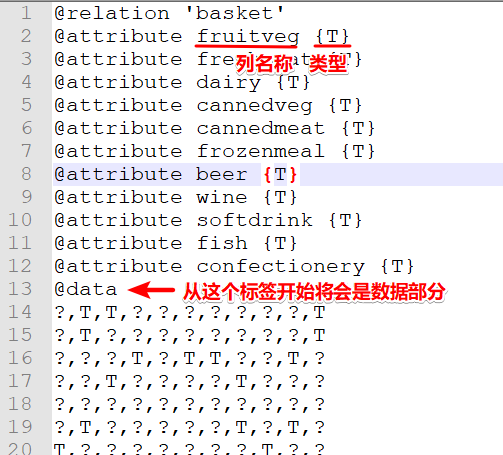
ARFF 格式指的是 Attribute-Relation File Format。可以理解为增加了列描述的 CSV 格式。文件主要分为头部(Head)信息和数据信息(Data)。头部信息定义了 Relation 和各列的 Attribute 的类型。数据部分内容和CSV一样,每列内容使用英文逗号隔开。例如下图就是一个 ARFF 格式数据。更多信息可以参考这篇文章。
【实验环境】
- Windows 操作系统。
- JDK
- Weka:Weka 的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),是一款免费的,非商业化(与之对应的是SPSS公司商业数据挖掘产品–Clementine )的,基于JAVA环境下开源的机器学习(machine learning)以及数据挖掘(data mining)软件。Weka 作为一个公开的数据挖掘工作平台,汇聚了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。
【实验资源】
实验报告模板下载
https://pan.baidu.com/s/1qqhcPcQotylS3PNP4f-edg#提取码vidt
实验数据下载
https://pan.baidu.com/s/10EebwAFcqwntmweVDQ470A#提取码h8c1
Weka 网盘下载:
https://pan.baidu.com/s/1dQEeVmqbyt11mZV7Uge_kQ#提取码2oev
如果网盘速度过慢,可以尝试从 Weka 官网下载:
https://sourceforge.net/projects/weka/files/weka-3-9/3.9.4/
【实验步骤】
1.在这个分析实验中,我们提取了某商店的购物清单其中的11个类别的数据。basket.txt 数据集的每一行表示一个购物清单的所有商品类别,商品类别经过去重处理,并且用Tab隔开。
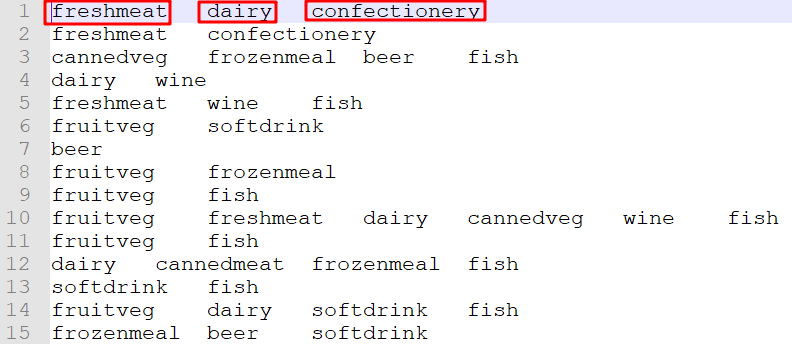
fruitveg:新鲜蔬菜
freshmeat: 鲜肉
dairy: 奶类制品
cannedveg: 蔬菜罐头
cannedmeat: 肉类罐头
frozenmeal: 冻肉
beer: 啤酒
wine: 红酒
softdrink: 软性饮料
fish: 鱼类
confectionery: 糕点糖果
- 为了满足 Weka 的后续分析需求。我们需要把购物类别清单的数据
basket.txt转换为 ARFF 格式数据basket.arff(ARFF 数据格式可以查看【实验原理】部分了解)。每一行的购物类别清单分别对应相应的列,数据集中的空值使用英文的问号?代替。
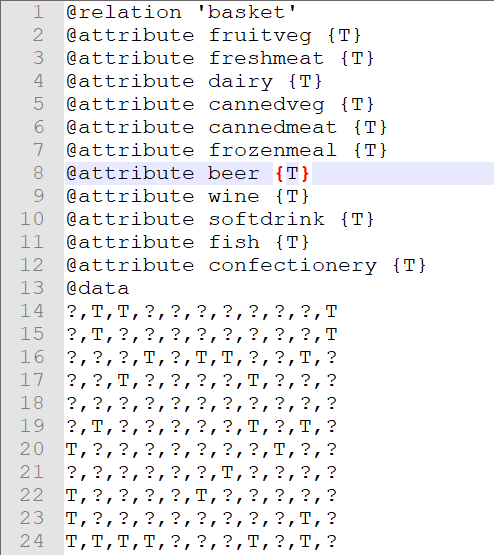
可以看到

表示为了
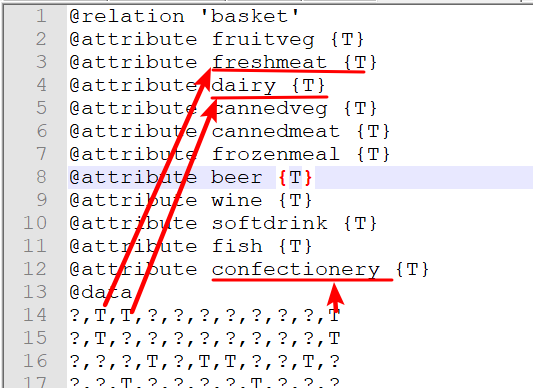
利用你所学过的知识,把basket.txt转换为basket.arff。形式不限,可以使用ETL工具,Python,Java,Spark 或 Hadoop 等,需要在实验报告记录你的思考过程,操作步骤或代码。以下为arff格式的固定表头,不能更改。
@relation 'basket'
@attribute fruitveg {T}
@attribute freshmeat {T}
@attribute dairy {T}
@attribute cannedveg {T}
@attribute cannedmeat {T}
@attribute frozenmeal {T}
@attribute beer {T}
@attribute wine {T}
@attribute softdrink {T}
@attribute fish {T}
@attribute confectionery {T}
@data
4.转换 arff 格式成功以后,我们将使用 Weka 的 Apriori 算法和 FPGrowth 算法,对购物清单类别进行关联分析,例如查看购买了 A 类商品的顾客有多大几率购买 B 类商品。
5.安装 Weka,过程略。
- 安装完毕以后,进入 Weka 的安装目录。
- 用文本编辑器打开
RunWeka.ini,修改编码支持UTF-8。这里的修改主要是为了 Weka 能够正常识别UTF-8编码的中文。
#fileEncoding=Cp1252
fileEncoding=utf-8

- 双击
Weka 3.9.4,打开 weka 的 Explorer。
- 打开文件
basket.arff。
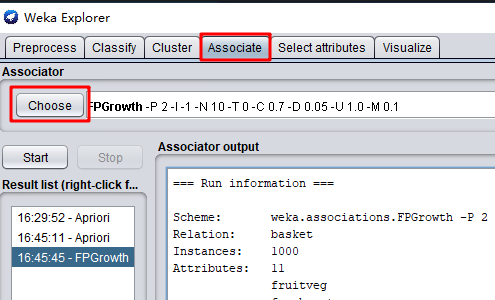
- 选择关联规则挖掘
associate,选择算法Choose。
- 选择 Apriori 算法,并点击 Apriori 配置算法参数。
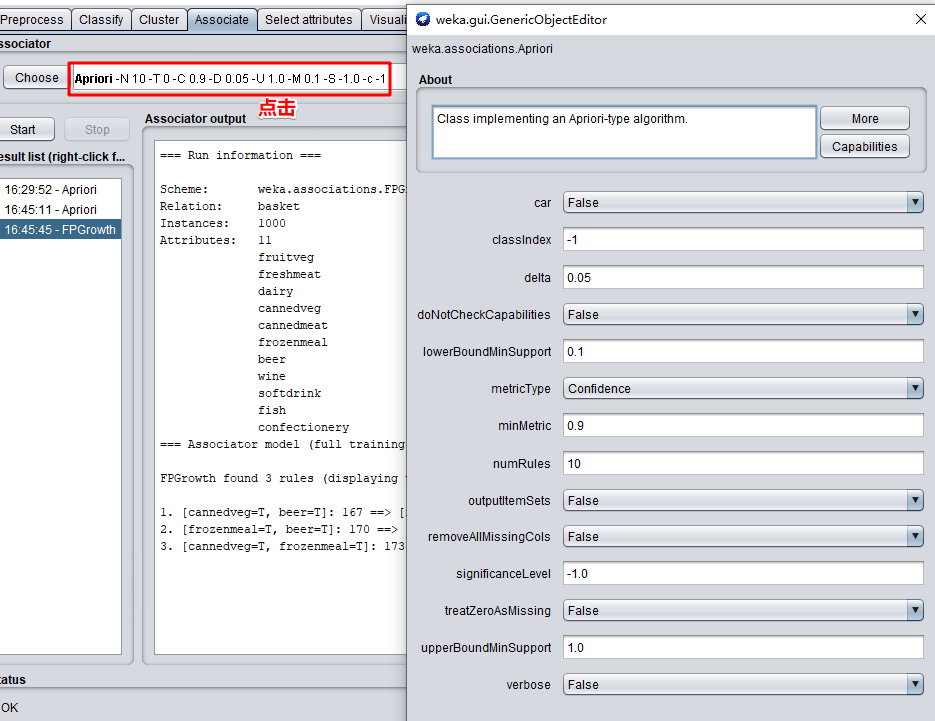
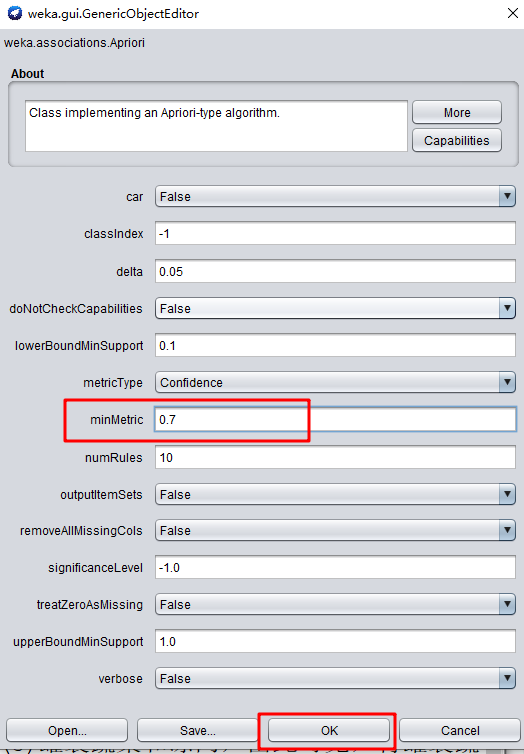
参数说明如下:
car: 如果设为真,则会挖掘类关联规则而不是全局关联规则。
classindex: 类属性索引。如果设置为-1,最后的属性被当做类属性。
delta : 以此数值为迭代递减单位。不断减小支持度直至达到最小支持度或产生了满足数量要求的规则。
lowerBoundMinSupport: 最小支持度下界。
metricType: 度量类型。设置对规则进行排序的度量依据。可以是:置信度(类关联规则只能用置信度挖掘),提升度(lift),杠杆率(leverage),确信度(conviction)。
在 Weka中设置了几个类似置信度(confidence)的度量来衡量规则的关联程度,它们分别是:
a) Lift : P(A,B)/(P(A)P(B)) Lift=1时表示A和B彼此无关联。这个数越大(>1),越表明A和B存在于一个购物篮中不是偶然现象,有较强的关联度.
b) Leverage :P(A,B)-P(A)P(B) Leverage=0时A和B彼此无关联,Leverage越大A和B的关系越密切
c) Conviction:P(A)P(!B)/P(A,!B) (!B表示B没有发生) Conviction也是用来衡量A和B的彼此无关联程度。从它和lift的关系(对B取反,代入Lift公式后求倒数)可以看出,这个值越大, A、B越关联。
minMtric: 度量的最小值。
numRules: 要发现的规则数。
outputItemSets: 如果设置为真,会在结果中输出项集。
removeAllMissingCols: 移除全部为缺省值的列。
significanceLevel: 重要程度。重要性测试(仅用于置信度)。
upperBoundMinSupport: 最小支持度上界。 从这个值开始迭代减小最小支持度。
verbose: 如果设置为真,则算法以冗余模式运行。
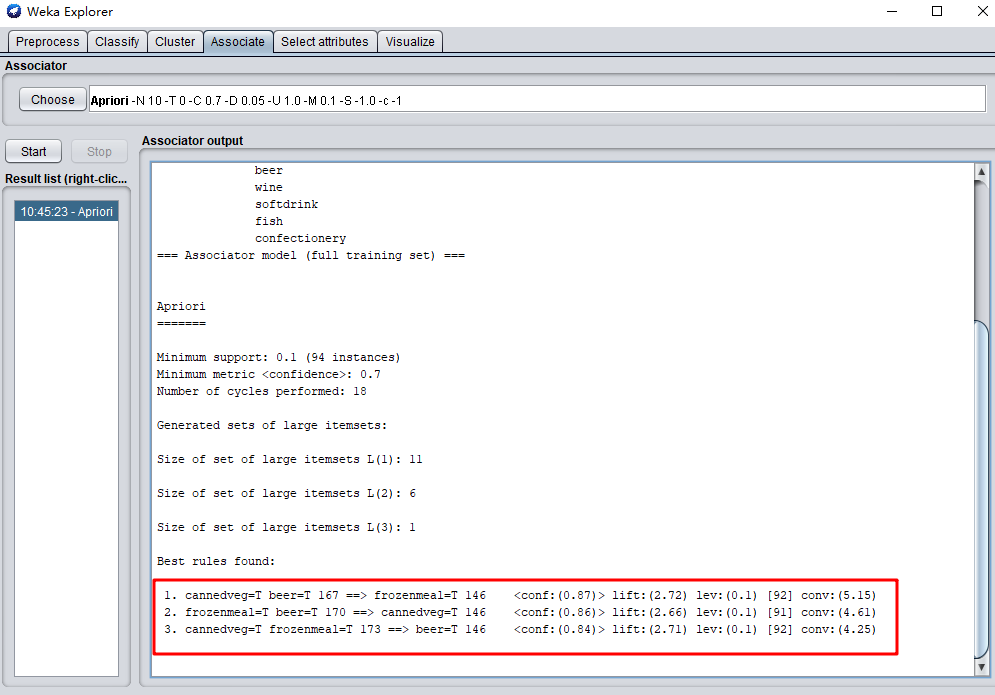
11.将minMetric设置为 0.7,设置好参数后点击start运行可以看到Apriori的运行结果:
- 然后使用FPGrowth再来计算一次,同样的minMetric设置为 0.7,结果如下:
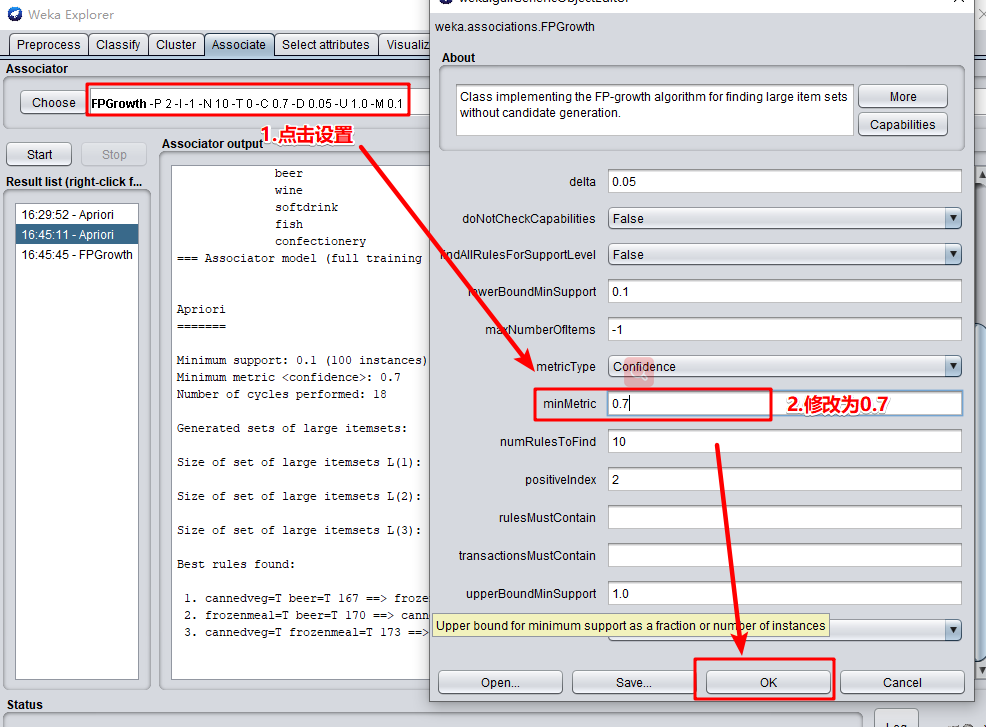
 可以看出,运行的结果是一样的,前三种有强关联规则的商品是
可以看出,运行的结果是一样的,前三种有强关联规则的商品是
- (1)买了罐装蔬菜和啤酒前提下,购买冻肉置信度(confidence)为0.87(146/167)
- (2)买了冻肉和啤酒前提下,购买罐装蔬菜置信度为0.86(146/170)
- (3)买了罐装蔬菜和冻肉前提下,购买啤酒的置信度为0.84(146/173)
由此可见,将罐装蔬菜,啤酒和冻肉摆放在一起比较能提高销售量。